압축(Zip)-파일 구조
ZIP FILE FORMAT(ZIP 파일 형식)
ZIP 파일 형식은 여러 데이터들을 압축, 보관하기 위한 파일형식이다. ZIP 파일은 하나 혹은 여러개의 파일들의 크기를 줄여 압축하고 하나의 파일로 묶어서 저장한다. ZIP 파일 형식에서는 다양한 종류의 압축 알고리즘을 사용합니다. 압축 알고리즘은 크게 두 개로 나뉠수 있는데, Entropy(huffman, Arithmetic)와 사전 코딩(LZ77, LZW)으로 나눌 수 있다. ZIP 파일은 많은 사람들이 huffman(허프만 부호화)알고리즘을 쓰고 있다고 오해를 할 수 있지만 ZIP은 Deflate 알고리즘을 사용합니다. Deflate 알고리즘은 위에 나와있는 특정 알고리즘이 아니라 사전 코딩에 있는 LZ77 알고리즘을 통해 데이터를 압축하고, 중복되는 내용의 위치와 길이를 huffman을 사용하여 한 번 더 압축합니다.
파일 확장자
파일 확장자는 파일의 형식이나 종류를 구분하기 위해서 파일명과 마침표(.)을 찍어 알파벳을 붙힌다. 쉽게 말해 파일의 성격을 구분 지을 수 있는 꼬리표이다.
ZIP 파일은 일반적으로 확장자를 ".zip"이나 ".ZIP"을 사용하고 있고, MIME(Multipurpose Internet Mail Extensions) 형식으로 application/zip 으로 표시하여 사용한다. 다양한 소프트웨어에서 파일 형식으로 사용되고 있고, 일반적으로 파일의 확장자가 다른 형태로 저장이 된다.
Ex) ".jar" , ".xpi" , ".pk3 / pk4" , ".odt" , ".docx" , ".apk"
ZIP 파일 구조
ZIP 파일의 일반적인 구조는 크게 3 개의 파일 구조(Local File Header, Central Directory, End of central directory record)로 되어 있다. 아래 그림을 보자.

Local File Header
압축 파일에 대한 기본 정보들이 포함되어 있다. Local File Header 시그니처, 압축 전 파일 크기, 압축 후 파일 크기, 파일 최종 수정 시간, 파일 최종 수정 날짜, CRC-32정보, 파일 이름, 파일 이름 길이 등등
File Name
압축된 파일 이름 형식에 대한 임의의 길이와 바이트 순서를 나타내고, 파일 이름의 최대 길이는 65536 문자를 초과할 수 없다.
File Data
임의의 길이로 구성된 바이트 배열 형태로 압축된 파일 컨텐츠이다. 파일이 비어 있거나 디렉토리를 포함하는 경우 이 배열은 사용되지 않지만 그 다음 Local File Header 제목은 해당 파일이나 디렉토리를 설명한다.
Central Directory
Local File Header의 확장된 데이터 뷰를 제공한다. Local File Header에 포함된 데이터를 더하여 파일 속성, 구조에 대한 로컬 기준을 가진다.
End of Central Directory record
모든 아카이브의 싱글 템플릿으로 제공하며 아카이브의 종료를 작성한다. 포함된 데이터에서 가장 중요한 데이터는 Central Dircetory 블록의 시작과 로컬 참조의 시작, 아카이브 레코드들의 숫자이다.
ZIP 파일 동작 원리
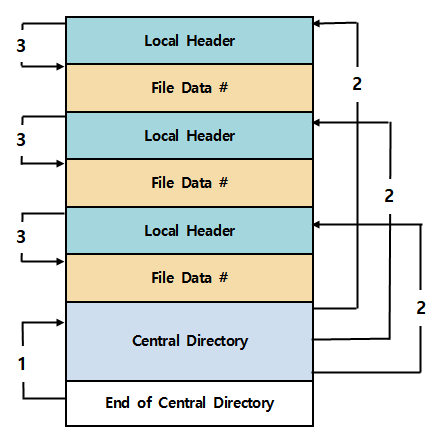
* 파일 이름을 설명할 때 header라는 단어를 많이 쓸 건데 의아해 하지 말고 알아보자.
표에서 Header라는 글자가 Local Header 밖에 없지만 Central Directory의 원래 이름은 Central Directory file header이다.
1. ZIP 파일을 최초 실행 시 먼저 End of Central Directory(EOCD)로 이동하게 됩니다.
2. End of Central Directory에서 들어 있는 정보를 읽어 Central Directory file header Offset으로 이동합니다.
3. 이동한 Central Directory file header offset에 들어 있는 정보의 값을 따라 이동을 해보면 Central Directory 시작 Offset으로 갑니다.
4. Central Directory의 시작 위치부터 값을 따라 이동하다 보면 내부에 존재하는 정보들을 통해서 Central Directory header의 개수 만큼 반복하여 Central Directory에 존재하는 Local Header Offset에 들어있는 값을 확인하고 End of Central Directory전 까지 정보를 읽습니다.
5. 확인한 Local Header Offset의 정보를 토대로 Local Header 시작 Offset으로 이동합니다.
6. Local Header Offset으로 이동한 뒤 정보를 읽어 해당되는 File Data로 이동하고 zip파일 사용자가 zip파일 내부 압축 데이터를 확인할 수 있게 됩니다. (압축해제를 한다)
7. Local Header의 개수 만큼 (순서 5 ~ 6)번을 계속 반복합니다.
이러한 순서로 ZIP파일이 실행될 때 데이터를 읽어 오게 되는데, 이제 실험을 해야 할 ZIP 파일을 가지고 자세한 ZIP파일 구조를 살펴 볼건데, 그 전에 빅 엔디안, 리틀 엔디안에 대해서 설명을 좀 하겠습니다.
엔디안
엔디안은 컴퓨터의 메모리와 같은 1차원 공간에 여러 개의 연속된 대상을 배열하는 방법을 뜻하고, 바이트를 배열하는 방법을 바이트 순서 라고 한다. 컴퓨터는 보통 32비트, 64비트로 표현 된다. 엔디안은 평균적으로 큰 단위가 앞에 나오는 빅 엔디안과 작은 단위가 앞에 나오는 리틀 엔디안으로 나뉩니다.
빅 엔디안
빅 엔디안 방식은 낮은 주소에 데이터를 높은 바이트 MSB(Most Significant Bit)부터 저장하는 방식이다. 이 방식은 평소 우리가 숫자를 사용하는 방식과 같은 방식이다. 쉽게 말해서 사람이 숫자를 읽고 쓰는 방법이 같아서 메모리상에 저장된 순서를 그대로 읽을 수 있으며, 리틀 엔디안에 비해서 이해 하기 수월하다. 빅 엔디안을 사용하는 CPU로는 대표적으로 AMD, RISC 계열이 있습니다.
리틀 엔디안
리틀 엔디안 방식은 낮은 주소에 데이터를 낮은 바이트 LSB(Least Significant Bit)부터 저장하는 방식이다. 이 방식은 평소 우리가 숫자를 사용하는 방식과 반대로 거꾸로 읽어야한다. 쉽게 말해서 사람이 숫자를 읽고 쓰는 방법을 반대로 읽고 메모리상에 저장된 순서도 반대로 읽으며, 빅 엔디안에 비해 이해 하기 어렵다. 리틀 엔디안을 사용하는 CPU로는 대표적으로 Intel 계열이 있다.
밑에 예제를 한번 이해를 하고 넘어 가봅시다.
| 저장 해야할 32비트 크기의 정수의 데이터 0x12345678 | ||||
| 메모리 주소 | 0x100 | 0x101 | 0x102 | 0x103 |
| 변수 값 | 0x12 | 0x34 | 0x56 | 0x78 |
<빅 엔디안 표현 방식>
빅 엔디안은 낮은 주소인 0x100에서 부터 높은 주소인 0x103까지 변수 값을 저장할 때 높은 바이트인 0x12부터 차례대로 0x34, 0x56, 0x78로 저장된다. 표현하면 0x12345678이 된다.
| 저장 해야할 32비트 크기의 정수의 데이터 0x12345678 | ||||
| 메모리 주소 | 0x100 | 0x101 | 0x102 | 0x103 |
| 변수 값 | 0x78 | 0x56 | 0x34 | 0x12 |
<리틀 엔디안 표현 방식>
리틀 엔디안은 낮은 주소인 0x100에서 부터 높은 주소인 0x103까지 변수 값을 저장할 때 낮은 바이트인 0x78부터 차례대로 0x56, 0x34, 0x12로 저장된다. 표현하면 0x78563412가 된다.

실습할 파일은 blog.txt가 ZIP파일로 압축된 blog.zip으로 실습하고 blog.txt안에 담겨있는 텍스트 내용은 Zip File Structure이다.
이제 End of Central Directory의 구조부터 하나씩 알아보도록 하자.
1. End of Central Directory Record

| 필드 | offset | Byte | 설명 |
| 1. | 0~4 | 4 | End of Central Directory Signature = 0x06054B50 (Big Endian : 0x504B0506) |
| 2. | 4~6 | 2 | The number of this disk (Containing the end of Central Directory Record) |
| 3. | 6~8 | 2 | Number of the disk on which the Central Directory strart |
| 4. | 8~10 | 2 | The number of Central Directory entries on this disk |
| 5. | 10~12 | 2 | Total number of entries in the Central Directory |
| 6. | 12~16 | 4 | Size of the Central Directory in Byte |
| 7. | 16~20 | 4 | Offset of the strat of the Central Directory on the disk on which the Central Directory Starts |
| 8. | 20~22 | 2 | The length of the following Comment field |
| 9. | 22~22+n | n | Optional Comment for the Zip file |
End of Central Directory구조는 표와 같이 구성 되어 있는데, 고정적인 데이터는 0x00 ~ 0x15까지이다.
실습파일인 blog.zip을 hxd에디터를 통해서 실제 Hex값을 하나씩 알아보도록 하자.

1. 0x00 ~ 0x03은 End of Central Directory Record의 Signature가 있는 필드입니다.
Signature는 고유의 값으로 변하지 않으므로 0x06054B50 (Big Endian : \x50\x4B\x05\x06)입니다.

2. 0x04 ~ 0x05는 첫번째 End of Central Directory가 담긴 디스크 번호를 말하고 Central Directory 레코드의 종료를 포함한다.

3. 0x06 ~ 0x07은 Central Directory가 시작되는 디스크의 번호를 의미한다.

4. 0x08 ~ 0x09는 이 디스크에 담긴 Central Directory Record의 개수를 의미한다.

5. 0x0A ~ 0x0B는 Central Directory Record의 총 개수 (파일 + 디렉토리)

6. 0x0C ~ 0x0F는 Central Directory의 총 크기 0x0000005A = Byte 90이다.

7. 0x10 ~ 0x13은 Central Directory의 시작위치를 뜻한다. 0x00000038 = Byte 56이다.

8. 0x14 ~ 0x15는 Comment 필드의 길이를 말하고 00 00이 아니라면 맨 뒤에 Zip file Comment가 적힌다.
End of Central Directory를 살펴본 결과를 표로 나타 내었습니다.
| End of Central Directory 정보 | |
| Signature | " 0x06054B50 " (4Byte) |
| Disk Number | 0 (2Byte) |
| Disk # w/cd | 0 (2Byte) |
| Disk entries | 1 (2Byte) |
| Total entries | 1 (2Byte) |
| Central directory size | 90Byte (4Byte) |
| Offset of cd wrt to starting disk | 56Byte (4Byte) |
| Comment len | 0 |
| ZIP file Comment | NULL |
2. Central Directory File Header

| 필드 | Offset | Byte | 설명 |
| 1. | 0~4 | 4 | Central Directory File Header Signature = 0x02014B50 (Big Endian : 0x504B0102) |
| 2. | 4~6 | 2 | Version made by |
| 3. | 6~8 | 2 | Version needed to extrack |
| 4. | 8~10 | 2 | General purpose bit flag |
| 5. | 10~12 | 2 | Compression method |
| 6. | 12~14 | 2 | File last modification time |
| 7. | 14~16 | 2 | FIle last modification date |
| 8. | 16~20 | 4 | CRC - 32 |
| 9. | 20~24 | 4 | Compressed size |
| 필드 | Offset | Byte | 설명 |
| 10. | 24~28 | 4 | Uncompressed size |
| 11. | 28~30 | 2 | File name length |
| 12. | 30~32 | 2 | Extra field length |
| 13. | 32~34 | 2 | File comment length |
| 14. | 34~36 | 2 | Disk number where file starts |
| 15. | 36~38 | 2 | Internal file attributes |
| 16. | 38~42 | 4 | External file attributes |
| 17. | 42~46 | 4 | Relative offset of local file header. This is the number of bytes between the start of the first disk on which the file occurs, and the start of the local file header. This allows software reading the central directory to locate the position of the file inside the ZIP file. |
| 18. | 46 | n | File name |
| 19. | 46 + n | m | Extra field |
| 20. | 46+n+m | k | File comment |
Central Directory File Header 파일 구조는 표와 같이 구성 되어 있는데, 고정적인 데이터는 0x00 ~ 0x2D까지이다.
실습파일인 blog.zip을 hxd에디터를 통해서 실제 Hex값을 하나씩 알아보도록 하자.
1. 0x00 ~ 0x03은 Central Directory File Header의 Signature은 0x02014B50 (Big Endian : 0x50\4B\01\02)입니다.
Central Directory File Header에서도 마찬가지로 시그니처는 고유의 값을 가지고 있습니다.

1. 0x00 ~ 0x03은 Central Directory File Header의 Signature은 0x02014B50 (Big Endian : 0x504B0102)입니다.

2. 0x04 ~ 0x05는 압축 생성 시 사용한 Version 정보이다.
실습파일을 보면 헥스 값이 0x003F이다. Upper Byte는 0x00 / Lower Byte는 0x3F이다.
상위 바이트는 00이므로 MS-DOS 6.3버전입니다. 6.3은 3F를 10진수로 바꾸면 63이다.
| 0x00 | MS - DOS and OS/2 (FAT / VFAT / FAT32 file system) | 0x0B | MVS(OS / 390 - Z / OS) |
| 0x01 | Amiga | 0x0C | VSE |
| 0x02 | OpenVMS | 0x0D | Acorn Risc |
| 0x03 | UNIX | 0x0E | VFAT |
| 0x04 | VM/CMS 0x05 : Atari ST | 0x0F | alternate MVS |
| 0x06 | OS / 2 H.P.F.S. | 0x10 | BeOS |
| 0x07 | Machintosh | 0x11 | Tandem |
| 0x08 | Z-System | 0x12 | OS/400 |
| 0x09 | CP/M | 0x13 | OS/X(Darwin) |
| 0x0A | Windows NTFS | 0x24 ~ 0xFF | unused *Lower Byte : zip specification version* |

3. 0x06 ~ 0x07은 압축을 해제할 때 필요한 버전으로 16진법인 0x000A를 10진법으로 계산하면 10이된다.
10은 1.0버전으로 1.0은 Default value가 된다.


4. 0x08 ~ 0x09는 FLAG 값이 들어 있습니다. 표를 보고 알아 봅시다. 0x0000이기 때문에 Encrypted File입니다.
| Bit | Purpose(목적) | Bit | Purpose(목적) |
| 0x00 | Encrypted File | 0x06 | Strong Encryption |
| 0x01 | Compression Option | 0x07 ~ 0x0A | Unused |
| 0x02 | Compression Option | 0x0B | Language Encoding |
| 0x03 | Data Descriptor | 0x0C | Reserved |
| 0x04 | Enhanced Deflation | 0x0D | Mask Header Values |
| 0x05 | Compressed Patched Data | 0x0E ~ 0x0F | Reserved |

5. 0x0A ~ 0x0B는 압축을 할 때 어떠한 방법으로 압축을 하였는지 알 수 있다. 0x0000이므로 No Compression이다.
| Byte | Method | Byte | Method |
| 0 | No Compression | 10 | PKWare DCL Imploded |
| 1 | Shrunk | 11 | Reserved |
| 2 | Reduced With Compression Factor1 | 12 | Compressed Using BZIP2 |
| 3 | Reduced With Compression Factor2 | 13 | Reserved |
| 4 | Reduced With Compression Factor3 | 14 | LZMA |
| 5 | Reduced With Compression Factor4 | 15~17 | Reserved |
| 6 | Imploded | 18 | Compressed Using IBM TERSE |
| 7 | Reserved | 19 | IBM LZ77 z |
| 8 9 |
Deflated Enhanced Deflated |
98 | PPMd Version l, Rev 1 |

6. 0x0C ~ 0x0D는 파일의 마지막 "수정시간" 입니다. 같이 한번 구해 봅시다. 그전에 컴퓨터의 시간 저장 형식에 대해서 설명할게요.
컴퓨터의 시간 저장 형식
MS-DOS Date/Time은 MS-DOS에서 사용된 시간 저장 형식으로 컴퓨터의 현재 날짜와 시간을 저장하고, 날짜와 시간을 각각 2바이트로 저장을 합니다.
< 기록 범위 >
시작 : 1980년 01월 01일 00 : 00 : 00 ( 00 : 21 : 00 : 00 )
끝 : 2107년 12월 31일 23 : 59 : 58 ( FF : 9F : BF : 7F )
< 구조 >
1. 날짜를 구할 때는 2바이트를 비트로 쪼개면 16비트가 됩니다.
앞에서부터 7비트는 연(YYYYYYY) 4비트는 월(MMMMM) 5비트는 일(DDDDD) 입니다.
Y : 1980년을 기점으로 한 연도 , M : 1월 = 1, 2월 2, .... 12월 = 12 , D : Day. 1 ~ 31일
2. 시간을 구할 때는 똑같이 2바이트를 비트로 쪼개서 16비트로 나눕니다.
앞에서부터 5비트는 시간(hhhhh) 6비트는 분(mmmmmm) 5비트는 초(sssss) 입니다.
h : hour. 0 ~ 23시 , m : minute. 0 ~ 59분 , s : second. 초 단위로 저장을 하되 *2로 들어갑니다. 0 ~ 29
이제 다시 풀이로 넘어가겠습니다.
풀이 : Big Endian으로 된 헥스 값은 0x6C58인데 Little Endian으로 변환을 시키면 0x586C 가 된다.
Little Endian으로 바꿔준 0x586C를 1byte값으로 나누면 0x58 , 0x6C가 되고 이걸 2진수로 변환을 시킵니다.
0x586C = 0101 1000 0110 1100으로 변환이 됩니다.
우리는 파일의 "수정시간"을 구해야 하니 2번 방법을 씁니다.
2진수로 변환시킨것을 2번 방법대로 나누면 h : (01011) , m : (000011) , s : (01100)이 됩니다.
01011 = 8 + 4 + 1 = 11 , 000011 = 2 + 1 = 3 , 01100 = 8 + 4 = 12 이니까 11시 03분 12초로 해석이 가능합니다.
하지만 초 단위는 *2를 해줘야 하기 때문에 정확한 시간은 11시 03분 24초가 됩니다.
참고로 ZIP파일의 수정시간이 아닌 ZIP파일 안에 들어있는 파일들의 최종 수정 시간입니다.

7. 0x0E ~ 0x0F는 파일의 마지막 "수정 날짜" 입니다. 바로 구해 봅시다.
풀이 : Big Endian으로 된 헥스 값은 0xC652인데 Little Endian으로 변환을 시키면 0x52C6이 된다.
Little Endian으로 바꿔준 0x52C6을 1byte값으로 나누면 0x52 , 0xC6가 되고 이걸 2진수로 변환을 시킵니다.
0x52C6 = 0101 0010 1100 0110으로 변환이 됩니다.
우리는 파일의 "수정날짜"를 구해야 하니 1번 방법을 씁니다.
2진수로 변환시킨 것을 1번 방법대로 나누면 Y : (0101001) , M : (0110) , D : (00110)이 됩니다.
0101001 = 32 + 8 + 1 = 41 , 0110 = 4 + 2 = 6 , 00110 = 4 + 2 = 6이니까 41년 06월 06일로 해석이 가능합니다.
하지만 날짜는 1980년을 기점으로 정의가 되어 있기 때문에 41 + 1980년을 해주면 2021년이다.
정확한 날짜와 시간은 2021년 06월 06일 11시 03분 24초에 파일이 최종 수정된 시간과 날짜입니다.

8. 0x10 ~ 0x13은 CRC-32 알고리즘으로써 데이터를 전송할 때 전송된 데이터에 오류가 있는지 없는지 확인 해주는 값이다. 쉽게 말해서 파일이 깨졌는지 안깨졌는지 알아볼 수 있지만, CRC-32가 모든 에러를 완벽하게 검출 하는것은 아니다.

9. 0x14 ~ 0x17은 압축된 데이터의 바이트 크기 입니다. 16진수로 0x12는 십진수 18이니까 압축된 데이터는 18Byte입니다.

10. 0x18 ~ 0x1B는 원본 데이터의 바이트 크기 입니다. 16진수로 0x12는 십진수 18이니까 압축된 데이터는 18Byte입니다.

11. 0x1C ~ 0x1D는 파일 이름의 길이 입니다. 실습파일의 이름이 blog이니까 blog.txt으로 8바이트가 됩니다.

12. 0x1E ~ 0x1F는 엑스트라 필드의 길이 입니다. 즉, 추가 예약 필드입니다. (현재는 사용하지 않습니다.)

13. 0x20 ~ 0x21은 파일의 주석 길이입니다. 주석은 달지 않았으므로 0바이트가 됩니다.

14. 0x22 ~ 0x23는 파일이 존재하는 디스크의 수입니다. ( 대부분 0 입니다. )

15. 0x24 ~ 0x25는 파일의 내부 속성값을 의미합니다. (MS-DOS 형식의 파일 속성 ) 다음 표를 보고 알아봅시다.
| Bit | Means | Bit | Means |
| Bit 0 | Apparent ASCII / text file | Bit 2 | control field records precede logical records |
| Bit 1 | reserved | Bit 3 ~ 16 | unused |

16. 0x26 ~ 0x29은 파일의 외부 속성값을 의미합니다. ( MS-DOS 형식의 확장 파일 속성 )

17. 0x2A ~ 0x2D는 Local Header 구조의 시작 주소.

18. 0x2E ~ 0x35는 파일의 이름 입니다. 하지만 파일의 이름은 원하는 대로 바꿀 수 있기 때문에 정해진 값은 없습니다.

19~20. (0x36 ~ a + b) 까지는 추가 필드 ( a ) + 추가 주석 ( b ) 이 나오는데 이 또한 정해진 값이 존재하지 않는다.
Central Directory File Header 구조를 살펴본 결과를 표로 나타냈습니다.
| Central Directory | |
| Signature (시그니처) | Little Endian = 0x02014B50 ( Big Endian : 0x504B0102 ) |
| Version (압축 생성 버전) | 0x 003F = MS-DOS 6.3버전 |
| Version needed(압축 해제 버전) | 0x000A = Default value |
| Flags (플래그) | 0x0000 = Encrypted File |
| Compression method ( 압축 유형 ) | 0x0000 = No Compression |
| File modification time (최종 파일 수정 시간) | 0x586C = 11시 03분 24초 |
| File modification data (최종 파일 수정 날짜) | 0x526C = 2021년 06월 06일 |
| CRC-32 ( 파일의 오류 확인 ) | 0xDC22ADDB |
| Compressed size ( 압축된 데이터의 크기 ) | 0x00000012 = 18Byte |
| Uncompressed size ( 원본 데이터 크기 ) | 0x00000012 = 18Byte |
| File name Length ( 파일 이름 ) | 0x0008 = 8Byte |
| Extra field Length (추가 예약 필드 ) | 0x0024 = 36Byte |
| File comment Length ( 파일 주석 길이 ) | 0x0000 |
| Disk # strat ( 디스크 수 ) | 0x0000 |
| Internal file Attribute ( 내부 파일 속성 ) | 0x0000 = Apparent ASCII / text file |
| External file Attribute ( 외부 파일 속성 ) | 0x00000020 |
| Offset of Local Header ( 로컬헤더 시작 주소) | 0x00000000 |
| File name (파일 이름) | blog.txt |
| Extra Field (추가 필드) | File name + a |
| File comment (파일 주석) | File name + a + b |
3. Local File Header

| 필드 | Offset | Bytes | 설명 |
| 1. | 0~4 | 4 | Local File Header Signature = 0x04034B50 ( Big Endian : 0x504B0304 ) |
| 2. | 4~6 | 2 | Version needed to extract |
| 3. | 6~8 | 2 | General purpose bit flag |
| 4. | 8~10 | 2 | Compression method |
| 5. | 10~12 | 2 | File last modification time |
| 6. | 12~14 | 2 | File last modification data |
| 7. | 14~18 | 4 | CRC - 32 |
| 8. | 18~22 | 4 | Compressed size |
| 9. | 22~26 | 4 | Uncompressed size |
| 10. | 26~28 | 2 | File name Length |
| 11. | 28~30 | 2 | Extra field Length |
| 12. | 30 | a | File name |
| 13. | 30+a | b | Extra field |
Local File Header 파일 구조는 표와 같이 구성 되어 있는데, 고정적인 데이터는 0x00 ~ 0x1D까지이다.
실습파일인 blog.zip을 hxd에디터를 통해서 실제 Hex값을 하나씩 알아보도록 하자.

1. 0x00 ~ 0x03은 Local File Header구조의 Signature는 0x04034B50 ( Big Endian : 0x50\4B\03\04 ) 입니다.
Local File Header에서도 마찬가지로 시그니처는 고유의 값을 가지고 있습니다.

2. 0x04 ~ 0x05는 압축해제를 할 때 필요한 버전이므로 Central Directory에서 본 버전 표랑 똑같으므로 0x0A = 10으로 변환되어 Default value이다.

3. 0x06 ~ 0x07은 Flag값이 들어있습니다. 마찬가지로 위에 Central Directory에 나와있는 Flag값 표랑 같으므로 Encrypted File입니다.

4. 0x08 ~ 0x09는 압축을 할 때 사용한 방법이 나와있습니다. 마찬가지로 위에 Central Directory에 나와있는 Method값 표랑 같으므로 No compression입니다.

5. 0x0A ~ 0x0B는 파일의 최종 "수정시간"을 뜻합니다.
풀이 : Big Endian으로 된 헥스 값은 0x6C58인데 Little Endian으로 변환을 시키면 0x586C 가 된다.
Little Endian으로 바꿔준 0x586C를 1byte값으로 나누면 0x58 , 0x6C가 되고 이걸 2진수로 변환을 시킵니다.
0x586C = 0101 1000 0110 1100으로 변환이 됩니다.
우리는 파일의 "수정시간"을 구해야 하니 2번 방법을 씁니다.
2진수로 변환시킨것을 2번 방법대로 나누면 h : (01011) , m : (000011) , s : (01100)이 됩니다.
01011 = 8 + 4 + 1 = 11 , 000011 = 2 + 1 = 3 , 01100 = 8 + 4 = 12 이니까 11시 03분 12초로 해석이 가능합니다.
하지만 초 단위는 *2를 해줘야 하기 때문에 정확한 시간은 11시 03분 24초가 됩니다.
참고로 ZIP파일의 수정시간이 아닌 ZIP파일 안에 들어있는 파일들의 최종 수정 시간입니다.
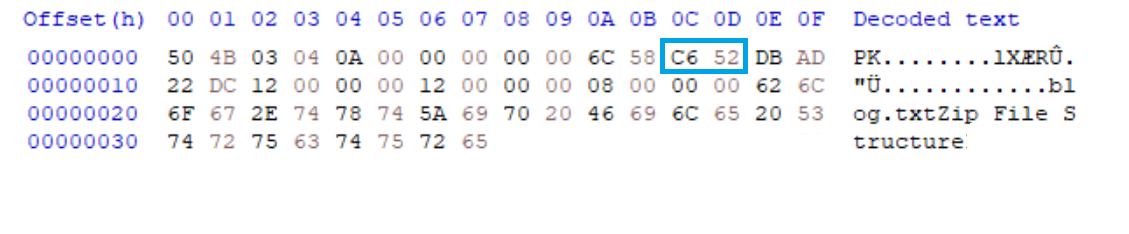
7. 0x0C ~ 0x0D는 파일의 최종 "수정날짜" 을 뜻합니다.
풀이 : Big Endian으로 된 헥스 값은 0xC652인데 Little Endian으로 변환을 시키면 0x52C6이 된다.
Little Endian으로 바꿔준 0x52C6을 1byte값으로 나누면 0x52 , 0xC6가 되고 이걸 2진수로 변환을 시킵니다.
0x52C6 = 0101 0010 1100 0110으로 변환이 됩니다.
우리는 파일의 "수정날짜"를 구해야 하니 1번 방법을 씁니다.
2진수로 변환시킨 것을 1번 방법대로 나누면 Y : (0101001) , M : (0110) , D : (00110)이 됩니다.
0101001 = 32 + 8 + 1 = 41 , 0110 = 4 + 2 = 6 , 00110 = 4 + 2 = 6이니까 41년 06월 06일로 해석이 가능합니다.
하지만 날짜는 1980년을 기점으로 정의가 되어 있기 때문에 41 + 1980년을 해주면 2021년이다.
정확한 날짜와 시간은 2021년 06월 06일 11시 03분 24초에 파일이 최종 수정된 시간과 날짜입니다.

8. 0x0E ~ 0x11는 CRC-32 알고리즘으로써 데이터를 전송할 때 전송된 데이터에 오류가 있는지 없는지 확인 해주는 값입니다.
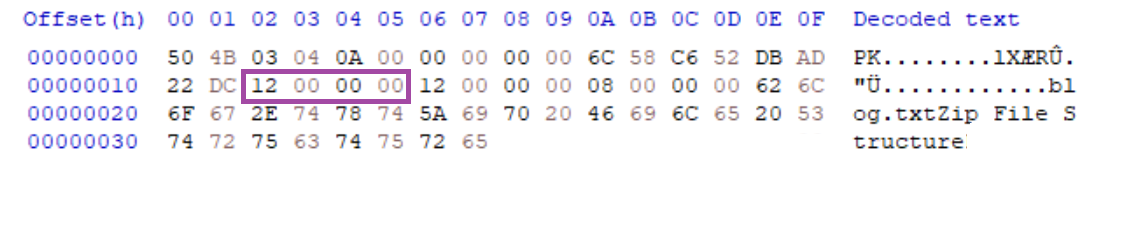
9. 0x12 ~ 0x15는 압축된 데이터의 바이트 크기 입니다. 16진수로 0x12는 십진수 18이니까 압축된 데이터는 18Byte입니다.

10. 0x16 ~ 0x19는 원본 데이터의 바이트 크기 입니다. 16진수로 0x12는 십진수 18이니까 압축된 데이터는 18Byte입니다.

11. 0x1A ~ 0x1B는 파일 이름의 길이 입니다. 실습파일의 이름이 blog이니까 blog.txt으로 8바이트가 됩니다.

12. 0x0C ~ 0x0D는 엑스트라 필드의 길이 입니다. 즉, 추가 예약 필드입니다. (현재는 사용하지 않습니다.)

13. 0x1E ~ 0x25는 파일의 이름 입니다. 하지만 파일의 이름은 원하는 대로 바꿀 수 있기 때문에 정해진 값은 없습니다.

14. 0x26 ~ 0x37은 추가 정보를 저장하는 추가 필드 입니다.
| Local Header | |
| Signature | Little Endian - 0x04034B50 (Big Endian : 0x504B0304) |
| Version needed | 0x000A = Default value |
| Flags (플래그) | 0x0000 = Encrypted File |
| Compression method ( 압축 유형 ) | 0x0000 = No Compression |
| File modification time (최종 파일 수정 시간) | 0x586C = 11시 03분 24초 |
| File modification data (최종 파일 수정 날짜) | 0x526C = 2021년 06월 06일 |
| CRC-32 ( 파일의 오류 확인 ) | 0xDC22ADDB |
| Compressed size ( 압축된 데이터의 크기 ) | 0x00000012 = 18Byte |
| Uncompressed size ( 원본 데이터 크기 ) | 0x00000012 = 18Byte |
| File name Length ( 파일 이름 ) | 0x0008 = 8Byte |
| Extra field Length (추가 예약 필드 ) | 0x0024 = 36Byte |
| File name (파일 이름) | blog.txt |
| Extra Field (추가 필드) | 0x65 72 75 74 63 75 72 74 53 20 65 6C 69 46 20 70 69 5A |
이렇게 해서 파일시스템 중 ZIP에 대해서 알아보았는데 설명을 쉽게 하긴 했지만 저가 참고하면서 작성을 한 분들의 사이트를 적어드릴테니 저꺼 보고 이해가 안된다 싶으면 찾아서 봐주세요 ㅎㅎ
<참고자료>
https://blog.forensicresearch.kr/3
ZIP File Structure Analysis
이번에 분석해볼 파일구조는 ZIP 파일입니다. ZIP 파일이란? Archive File Format 중 하나로 무손실 데이터 압축 방식을 지원합니다. 여러 알고리즘을 사용하고 있었지만 현재에는 Deflate 알고리즘을 대
blog.forensicresearch.kr
압축_집(Zip)구조 형태 원리 분석
ZIP 파일 형식이란 데이터를 압축, 보관하기 위한 파일형식이다. ZIP 파일은 하나 혹은 여러 개의 파일들을 그 크기를 줄여 압축하고 하나로 묶어 저장한다. ZIP 파일 형식에서는 다양한 종류의 압
jmoon.co.kr
https://koromoon.blogspot.com/2020/02/zip-file-format.html
ZIP File Format
White-Hat Hacker
koromoon.blogspot.com
https://users.cs.jmu.edu/buchhofp/forensics/formats/pkzip.html#centraldirectory
The structure of a PKZip file
Overview This document describes the on-disk structure of a PKZip (Zip) file. The documentation currently only describes the file layout format and meta information but does not address the actual compression or encryption of the file data itself. This doc
users.cs.jmu.edu
https://www.mql5.com/en/articles/1971#c1_1
Handling ZIP Archives in Pure MQL5
The MQL5 language keeps evolving, and its new features for working with data are constantly being added. Due to innovation it has recently become possible to operate with ZIP archives using regular MQL5 tools without getting third party DLL libraries invol
www.mql5.com