MFT(Master File Table) 구조
지난 시간에 NTFS 파일 시스템을 배웠습니다. 이번에는 NTFS 파일 시스템에서 가장 중요한 MFT 파일의 구조를 배워 보겠습니다.
MFT 파일이란?
MFT 파일은 NTFS 파일 시스템에서 파일, 디렉터리, 메타데이터를 모두 "파일" 형태로 관리하는 파일 입니다.
예전에 배웠던 FAT 파일 시스템에서 본 디렉터리 엔트리의 상위 개념이라고 이야기 할 수 있습니다. 그리고 나중에 구조를 보시면 아시겠지만 FAT 파일 시스템과는 좀 많이 다르기 때문에 설명에 있어 길어지는 점 양해를 부탁바랍니다.
MFT 영역의 구조를 한번 보겠습니다.

MFT 영역은 위 그림을 보면 아시겠지만 VBR 영역 이후에 오게 됩니다. 그림에서는 이어서 바로 오는 것 처럼 표현이 되었지만 실제로는 VBR과 MFT 사이의 물리적인 공간이 존재하므로 FAT 파일 시스템처럼 FAT 영역이 부트 섹터 이후에 바로 오는 것과는 다릅니다. 즉, VBR 이후의 모든 볼륨 영역 가운데 아무곳에나 존재할 수 있다는 것을 위에서 나타내봤습니다. 또한, 각 파일의 위치 및 속성, 시간정보, 이름, 크기등의 파일 메타 데이터는 MFT Entry 라는 특별한 구조를 통해서 저장됩니다. MFT는 NTFS 상에 존재하는 모든 파일의 MFT Entry를 가지고 있는 모음입니다.
MFT 영역은 파일 시스템 상의 파일 수에 따라 동적으로 할당 됩니다.
Microsoft 공식 문서를 보시면 파일 시스템의 전체 영역 중 12.5% 정도가 MFT 영역으로 할당 되어 있으며, MFT Entry는 번호로 매겨지며 0~15번은 파일 시스템의 예약된 영역으로 사용됩니다.
지금부터는 실습을 통해서..$MFT 영역을 찾아 보도록 하겠습니다.

NTFS로 초기화 된 512MB짜리 가상 디스크를 만들어서 실습을 진행했습니다.
NTFS 파일 시스템에서 BPB영역 구조는 다음과 같습니다.

0x30 ~ 0x37까지 $MFT의 클러스터 시작 위치이고, 0x38 ~ 0x3F까지 $MFTMirr의 클러스터 위치였습니다.

값을 계산을 해보면 $MFT의 위치는 0xA9AA * 8 = 347,472 섹터, $MFTMirr의 위치는 0x02 * 8 = 16 섹터입니다.
8을 곱해주는 이유는 0x0D를 보시면 클러스터 당 섹터의 수가 08로 되어있기 때문입니다! 직접 한번 보시죠!


아까 계산했던 것과 같이 두 섹터의 위치에 들어있는 데이터들이 동일함을 알 수 있습니다.
이제는 MFT 영역에서 MFT Entry의 구조적인 부분을 보겠습니다.

MFT Entry는 각 엔트리당 1024 바이트로 이루어진 구조이며, 각 파일 및 디렉터리마다 하나씩 생성되어 해당 파일 및 디렉터리의 정보를 관리합니다. 쉽게 말해서 실제 파일 및 디렉터리의 메타 정보 저장을 위해 사용합니다.
MFT Entry 0~15번은 예약된 영역이라고 했는데, 각 엔트리 번호에 들어있는 기능들을 한번 봅시다!

MFT 영역은 크게 이런 형태로 되어 있습니다.
이제는 MFT Entry의 영역을 하나씩 파헤쳐 보도록 해봅시다!

MFT Entry Structure는 위 표 처럼 되어있다.
MFT Entry Header
MFT Entry Header를 보겠습니다.
MFT Entry Structure 중 가장 먼저 나오는 MFT Entry Header는 MFT Entry의 메타데이터 정보를 담고 있는 48바이트의 영역입니다.

이 48바이트가 이제 MFT Entry Header 영역인데 데이터가 각각 어떤 정보를 담고 있는지 한번 봅시다.


MFT Entry Header는 Header 정보인 만큼 다양한 메타 데이터를 가지고 있다.
위의 정보 중에서 중요한 필드는 4개 정도로 추려지는데 한번 보겠습니다.
Main Field = Offset to Fixup Array, $LogFile Sequence Number, Offset to File Attribute, File Reference to Base Entry
Base & Non-base MFT Entry
Base & Non-base MFT Entry를 배워 보겠습니다.
MFT Entry Header에서 0x20 ~ 0x27까지의 데이터가 Base Entry or Non-base Entry 참조 주소를 담고 있었습니다.
파일의 속성 내용이 클 경우에 하나 이상의 MFT Entry를 사용하게 된다.
Base MFT Entry는 해당 파일의 첫 MFT Entry를 사용하게 된다.
Non-base MFT Entry는 Base MFT Entry를 제외하고 나머지 부분을 담고 있는 Entry이다.

어떤 파일에 대한 정보가 너무 많아서 하나의 MFT Entry에 담기가 불가능할 경우 여러개의 MFT Entry를 사용한다.
처음 해당하는 MFT Entry 를 Base MFT Entryt 라고 이야기 하며, 그외에는 Non-Base MFT Entry라고 이야기한다.
예를 한번 보겠습니다.
→ 22번 MFT Entry의 경우 File Reference to Base MFT Entry가 "19 00 00 00 00 00 XX XX"
(XX XX 는 25번 MFT Entry의 Sequence Number 값을 사용한다)
→ 27번 MFT Entry의 경우 File Reference to Base MFT Entry가 "19 00 00 00 00 00 XX XX"
(XX XX 는 25번 MFT Entry의 Sequence Number 값을 사용한다)
→ 25번 MFT Entry의 경우 File Reference to Base MFT Entry가 "00 00 00 00 00 00 00 00" 으로 사용한다
즉, File Reference to Base MFT Entry 자리가 00 00 00 00 00 00 00 00 이면 Base MFT Entry 구조, 00 00 00 00 00 00 00 00이 아니면 Non-Base MFT Entry 구조이다.
지금 제가 공부하고 있는 가상 디스크는 00 00 00 ~ 으로 되어있음을 확인할 수 있습니다.

File Reference Address

MFT Entry Address는 48 비트의 고유한 주소를 가진다.
아래와 같은 계산식을 이용해서 File Reference Address를 구한다.
File Reference Address = Sequence Number + MFT Entry Address
Sequence Value는 MFT Entry Header의 0x10 ~ 0x11에 존재합니다.
Fixup Array
MFT Fixup Array 영역을 살펴보기 전에 이 영역이 같는 의미를 한번 보도록 하자.
Fixup을 해석하면 수리하다, 고치다 라는 의미를 가지는데 NTFS에서 Fixup의 구조를 둔 이유는 신뢰성을 높이기 위한 방안이다. MFT 엔트리는 기본적으로 1,024Byte이므로 2개의 섹터를 사용한다. 이처럼 NTFS를 구성하는 데이터가 하나 이상의 섹터를 사용할 경우 섹터의 마지막 2바이트 값을 별도로 저장하고, 해당 위치는 Fixup의 값 2바이트가 들어가게 된다. 이로 인해서 섹터의 내용이 비정상적으로 변경될 경우, 오류를 사전에 찾아낼 수 있기 때문에 MFT Entry의 데이터 무결성을 판단하는 영역이라고도 불린다.
Fixup Array는 MFT Entry 구조 외에도 다양한 구조에서 사용이 된다.
- MFT Entries
- INDX Recodes
- RCRD Records
- RSTR Records
Fixup Array를 이론적으로 이해해보자!

이제 실습 파일을 가지고 간단하게 알아봅시다.
먼저, MFT 엔트리 헤더에서 Fixup과 관련된 필드는 2개가 있다. 하나는 "Offset to fixup array" 이고, 또 다른 하나는 "Number of entries in fixup array" 이다.

- Offset to fixup array : 0x0030
- Number of entries in fixup array : 0x0003
위 처럼 값을 가질 때, 총 6바이트가 fixup 구조에 의해 대신하는 값을 저장하는 배열 크기가 된다. 즉, 주황색 박스가 fixup array의 영역이고, 시그니처와 배열을 포함해서 8bytes의 크기를 갖는다.
fixup array의 시그니처 값은 0x0300으로 설정되어 있다. 그러면 섹터의 마지막 2bytes도 0x0300의 시그니처 값을 가져야 할 것이다.


섹터 0과 섹터1의 마지막 2byte의 값이 0x0300으로 동일한 것을 확인했다.
마지막으로 fixup 구조로 대체된 값을 원래대로 되돌리는 방법을 설명하겠다. 먼저 fixup 영역은 2bytes 값인 0x0300을 3번 반복하게 될 것이다. 총 크기가 8byte값이지만 MFT Entry는 2섹터의 크기를 가지므로 Signature( 2byte ) + 0번 섹터의 마지막 2byte + 1번 섹터의 마지막 2byte = 0x0300 0300 0300의 값이 대체되기 전의 값일 것이다.

동시에 0번 섹터의 마지막 2byte와 1번 섹터의 마지막 2byte는 원래 가졌던 값인 0x0000으로 변경 시켜준다.


이처럼 마지막에 나오는 2byte가 하나라도 변조가 되어 있다면 무결성이 훼손되는 것입니다.
Attributes (속성)
속성 영역이라고 불리는 Attributes 영역은 MFT 구조에서 가장 큰 비중을 차지하고 있으며, 가장 중요한 영역입니다.
가장 방대한 속성 값이 존재하며, 디렉터리 및 파일의 모든 내용을 담고 있는 영역이기도 합니다.
각 파일의 메타 데이터는 속성이라는 구조를 통해서 표현을 하게 된다.
Attributes 영역은 여러개의 속성 구조로 관리가 되는데 하나의 속성 구조에는 속성 헤더와 속성 내용을 가지게 됩니다.
MFT Attribute는 Attribute의 크기에 따라서 Resident 속성과 Non-Resident 속성으로 나뉘어진다.
Resident Attribute는 속성 헤더 바로 뒤에 바로 속성 내용이 저장이 되며, MFT Entry의 내부에 존재한다.
Non-Resident Attribute는 속성의 내용이 크기가 너무 커서 별도의 클러스터에 저장이 되며, MFT Entry의 외부에 존재한다.
$DATA 속성의 경우에는 예외적으로 파일의 크기에 따라서 속성이 달라진다.
파일의 크기가 700byte 이하일 경우 Resident 속성을 가지며, 700byte 이상이면 Non-Resident Attribute 속성을 가진다.
속성의 종류를 한번 보겠습니다.

나중에 설명을 하겠지만, 일반적인 파일의 경우 위 많은 속성 중 아래 그림과 같이 3가지의 속성만 옵니다.
그래서 3가지 속성에 대해서만 잘 알고 있어도 대부분의 파일을 분석할 수 있다.

hex값을 한번 보면 Fixup 배열 이후에 $STANDARD_INFORMATION 속성이 나오고 이어서 $FILE_NAME 속성이 오는 것을 알 수 있다.

Common Attribute Header
Common Attribute Header는 이름 그대로 해석을 한 것과 같이 Attribute Header의 가장 기본적인 포맷이다.
구조를 한번 보겠습니다.

이 구조는 Resident Attribute Header와 Non-Resident Attribute Header에 필수적으로 들어가는 구조이다.
Common Attribute Header에 해당하는 파일 데이터를 확인 해보겠습니다.

이 영역들이 Common Attribute Header에 포함 되어있는 정보인데 구체적으로 한번 보겠습니다.

Resident Attribute Header
Resident Attribute Header는 위에 보셨던 Common Attribute Header의 0x00 ~ 0x0F는 같은 값을 가지고, 그 이후에 16byte는 다른 값을 가진다.
구조를 한번 보겠습니다.

Resident Attribute Header에 해당하는 파일 데이터를 확인 해보겠습니다.

Resident Attribute Header에 포함되어 있는 정보를 구체적으로 보겠습니다.

Non-Resident Attribute Header
Non-Resident Attribute Header도 Common Attribute Header의 0x00 ~ 0x0F는 같은 값을 가지고있다. 하지만 Resident Attribute Header와는 구조가 살짝 다른데, 정확한 구조를 한번 보겠습니다.

Non-Resident Attribute Header에 해당하는 데이터 파일을 보겠습니다.

Non-Resident Attribute Header에 포함되어 있는 정보를 구체적으로 보겠습니다.

Cluster Runs
속성이 Non-Resident 일 경우 별도의 클러스터를 할당 받아 내용을 저장한다고 했습니다.
하지만 할당 받는 클러스터는 파일에 따라서 수천, 수만개가 되는데 예를 들어서 700MB의 동영상 파일이라고 가정하면, 4KB의 클러스터를 사용할 경우 20만개의 클러스터가 사용됩니다. 이 클러스터들은 하드디스크의 여유 공간이 너무 많아 연속적으로 할당이 될 수 있지만, 대부분은 비 연속적으로 할당됩니다. 이렇게 비연속적으로 할당 된 클러스터를 효과적으로 관리하기 위해서 NTFS의 $MFT 파일에서 클러스터 런(Cluster Runs)라는 것을 사용합니다.
클러스터 런의 예시를 확인해 보면 다음과 같습니다.

위 보여지는 데이터를 기반으로 런 리스트를 그림을 그려보겠습니다.

위의 구조를 보면 Data Run의 첫 바이트 기준으로 Data Run Length, Data Run Offset 길이가 정해진다.
Logical Cluster Number (LCN) : 볼륨의 첫 번째 클러스터부터 순차적인 번호 = Data Run Offset
Virtual Cluster Number (VCN) : 파일의 첫 번째 클러스터부터 순차적인 번호 = Data Run Length
첫 바이트가 31인데, 이 31이 가지는 의미는 다음과 같습니다.
Data Run Length (1Byte)의 길이가 1바이트, Data Run Offset (3Byte) 3바이트의 크기를 가진다는 것입니다. 만약 24라고 하면 Data Run Length의 길이는 4바이트, Data Run Offset의 길이는 2바이트의 값을 가지게 됩니다.
현재 $MFT 파일의 MFT Entry를 예시로 들고 있기 때문에 속성의 내용이 매우 깁니다. 따라서 Data Run의 크기가 MFT 파일의 크기일 것입니다.
Data Run Length가 1바이트 즉, 0x40이므로 64 클러스터의 의미를 담고 있습니다.

1 클러스터당 4KB의 값을 가지고 있기 때문에 64 * 4 = 256KB의 크기를 가지게 됩니다.
실제로 FTK Imager를 가지고 분석 중인 디스크에서 MFT파일을 추출하니까 동일한 크기를 가지고 있음을 알 수 있었습니다.

이렇게 대부분의 파일은 $DATA의 값이 크기 때문에 Non-Resident이며, 이는 클러스터 런을 가지므로 NTFS 파일 시스템에서 직접 카빙도 가능 합니다. Data Run Offset이 0x00A9AA 이므로 43,434 클러스터입니다.
43434 * 8 = 347,472 섹터이므로 해당 섹터로 가보면 MFT 파일이 있는 것을 확인할 수 있습니다.

이제 카빙을 진행해봐야 하는데, 여기서는 해당 파일의 사이즈가 64 클러스터 였기 때문에 512 섹터가 크기가 됩니다.
왜냐면 1 클러스터당 8개의 섹터를 가지고 있기 때문에 64 * 8 = 512섹터가 되기 때문입니다.
그래서 위에서 나온 347,472 섹터 + 512 섹터는 347,984 섹터가 마지막 섹터이다.
0xA9AA00 ~ 0xA9E9FF(size : 262,144(0x40000)) 까지 카빙을 한 뒤 원본 파일과 Hash 비교를 진행 해보겠습니다.

동일한 결과를 얻을 수 있습니다.
Attribute Types
지금부터는 MFT 영역에서 가장 중요한 속성 타입들을 알아 보겠습니다.
일반적으로 파일들을 3가지의 속성을 가지고 있습니다.
- $STANDARA_INFORMATION : 파일의 생성, 접근, 수정 시간, 소유자 등의 정보가 담겨 있다.
- $FILE_NAME : 파일이름(유니코드), 파일의 생성, 접근, 수정 시간 등의 정보가 담겨 있다.
- $DATA : 파일 내용
대부분 $ 표시 이후에 대문자 문자열이 오면 속성의 이름을 의미합니다.
단, $ 이후 첫 글자만 대문자라면 메타데이터 파일을 의미합니다.
Attribute - $STANDARD_INFORMATION (0x10)
먼저, $STANDARD_INFORMATION은 속성 식별 값이 0x10입니다. 속성들 중 타입 번호가 가장 낮기 때문에 MFT 엔트리 내의 속성들 중 가장 처음에 위치하며, 윈도우 NT에서는 48바이트의 크기를 가지고 있습니다.
$STANDARD_INFORMATION의 구조를 한번 보겠습니다.

예시로 $STANDARD_INFORMATION를 한번 보겠습니다.

이 영역은 Fixup Array를 설명할 때 잠깐 봤었는데, 지금은 해당 영역이 가지고 있는 정보들을 구체적으로 한번 보겠습니다.

다음은 0x20 ~ 0x23의 값에서 가지고 있는 Flags 필드에 대한 자세한 값을 나타내는 표 입니다.

Attribute - $ATTRIBUTE_LIST (0x20)
다음 $ATTRIBUTE_LIST는 속성 식별 값 0x20을 가지는 속성이며, $STANDARD_INFORMATION 속성 이후에 나오는 속성입니다.
$STANDARD_INFORMATION 속성은 모든 파일에 존재하지만 파일이나 $ATTRIBUTE_LIST는 특별한 경우에 존재합니다.
디렉터리의 속성의 크기가 커지면 하나의 MFT 엔트리에 담을 수 없기 때문에 그럴 경우에 사용하게 됩니다. $ATTRIBUTE_LIST구조를 한번 보겠습니다.

예시로 $ATTRIBUTE_LIST를 한번 보겠습니다.

분석을 진행하던 512MB 가상 디스크에는 볼 수 없었던 데이터라 제 SSD를 그냥 가져왔습니다.
Attribute Header를 제외하고 나머지를 확인 해보면 데이터의 크기가 커서 클러스터 런이 있는 것을 확인할 수 있었습니다.
클러스터 런을 살펴보기 전 $ATTRIBUTE_LIST에 포함되어 있는 정보를 한번 보겠습니다.

클러스터 런을 살펴보면, 31로 되어 있으니 Data Run Length가 1바이트고 Data Run Offset이 3바이트입니다.
첫 번째 클러스터 런을 해석하면 다음과 같습니다.
- Data Run Length = 0x01
- Data Run Offset = 0x668B6A
결국, $ATTRIBUTE_LIST 속성을 표현하기 위해 클러스터 하나를 사용하고 있고, 해당 클러스터 오프셋은 0x668B6A입니다.
섹터를 한번 찾아가보면 668B6A = 6,720,362 * 8 = 53,762,896 섹터에 위치합니다.

위 Hxd 데이터 값으로 $ATTRIBUTE_LIST에 대한 내용을 정리해 보면 다음과 같습니다.

이렇게 나누면 되는데 자세한 것은 표를 보겠습니다.

아마 이 표를 처음보면 이해가 안되실 거라 생각하고, 간단하게 $DATA에 대해서만 짚고 넘어 가겠습니다.

속성 타입부터 알아보겠습니다. 젤 앞에 나오는 값이 0x80으로 $DATA 속성 타입을 가지고 있습니다. 이때 3바이트를 건너 띈 2바이트가 엔트리 크기가 됩니다. 다음 1바이트는 이름 길이, 다음 1바이트는 이름의 위치가 됩니다. 이제 빨간색으로 표시된 부분이 시작 VCN입니다. 그리고 다음 주황색으로 표시된 부분 8바이트가 속성 파일 참조 주소입니다. 다음 초록색으로 표시 된 부분 1바이트가 속성 ID입니다. 이렇게 이제 계산을 하다보면 제가 만들었던 표 처럼 나올텐데, 혹시나 제가 오타가 있을 수 있으니 언제나 피드백 해주세요!!
Attribute - $FILE_NAME (0x30)
$FILE_NAME 속성은 $STANDARA_INFORMATION과 함께 NTFS의 모든 파일에 기본적으로 존재하는 속성입니다. 속성의 이름에서 알 수 있듯이 파일의 이름을 저장하기 위해 존재하며, 파일의 이름 이외에도 디렉터리의 이름도 저장할 수 있습니다.
$FILE_NAME 속성의 구조를 보겠습니다.

예시로 $FILE_NAME을 한번 보겠습니다.

$FILE_NAME은 0x30으로 시작되는 부분을 의미합니다. 자세한 정보를 보겠습니다.

File Reference Address of Parent Directory를 자세히 보면, 6바이트 | 2바이트로 나뉘어 집니다.
- 6 바이트 : 부모 디렉터리의 파일 레코드의 숫자
- 2 바이트 : 부모 디렉터리의 시퀀스 숫자
Flags에 대한 값은 표로 보겠습니다.

다음은 이름의 표현 형식을 자세히 보겠습니다.

Attribute - $OBJECT_ID (0x40)
$OBJECT_ID는 속성 식별 값 0x40을 가지는 속성입니다. 모든 MFT 레코드에는 고유한 GUID 값이 할당 되는데 구조를 한번 보겠습니다.

예시로 $OBJECT_ID을 한번 보겠습니다.

속성 식별값을 보면 0x40으로 되어 있는것을 볼 수 있다. $OBJECT_ID에 포함되어 있는 정보를 확인해보면 다음과 같습니다.

Attribute - $SECURITY_DESCRIPTOR (0x50)
$SECURITY_DESCRIPTOR는 속성 식별 값 0x50을 가지는 속성입니다.
$SECURITY_DESCRIPTOR는 파일이 옮겨지거나 이름이 바뀌어도 그대로 유지되는 파일이나 디렉터리 고유의 숫자를 가집니다.
$SECURITY_DESCRIPTOR 구조를 한번 보겠습니다.

예시로 $SECURITY_DESCRIPTOR를 한번 보겠습니다.

$SECURITY_DESCRIPTOR에 포함되어 있는 정보를 확인해 보면 다음과 같습니다.

Attribute - $VOLUME_NAME (0x60)
$VOLUME_NAME은 속성 식별 값 0x 60을 가지고 있는 속성입니다. 해당 속성은 단순히 이름에서 아시다시피 볼륨 명을 다루는 속성입니다.
구조를 한번 보겠습니다.

다른 속성들에 비하면 엄청 단순한 구조를 가지고 있습니다.
$VOLUME_NAME에 해당하는 예시를 보겠습니다.

$VOLUME_NAME에 포함 되어있는 정보를 보겠습니다.

볼륨명을 변경함에 따라 변하는 정보가 있습니다.
제가 가져온 데이터는 볼륨명이 NTFS라고 되어 있는데 이는 사용자가 임의로 변경한 것이 아닌 처음부터 설정되어 있는 값입니다.
볼륨 이름 및 드라이브 문자를 변경하지 않은 데이터와 볼륨 이름 및 드라이브 문자를 변경한 뒤의 데이터를 비교 해보겠습니다.
먼저, 볼륨 이름 및 드라이브 문자를 변경하기 전 데이터는 다음과 같습니다.

볼륨 이름 및 드라이브 문자를 변경한 후 데이터를 보겠습니다.

0x60 속성 식별값을 가지는 $VOLUME_NAME Attribute를 확인해보면 변경한 볼륨 이름이 생성 된 것을 확인할 수 있습니다.
Attribute - $VOLUME_INFORMATION (0x70)
$VOLUME_INFORMATION은 속성 식별 값 0x70을 가지는 속성입니다. 해당 속성 값은 볼륨의 버전 및 상태를 다루는 속성입니다.
구조를 한번 보겠습니다.

$VOLUME_INFORMATION에 해당하는 예시를 보겠습니다.

$VOLUME_INFORMATION에 저장되어 있는 정보를 한번 보겠습니다.

Flags 값에 대한 것도 표로 보겠습니다.

Attribute - $DATA (0x80)
일반적인 파일의 경우 MFT 엔트리는 기본적으로 3개의 속성이 존재하는데, 그 중 한 개가 $DATA 파일이다.
앞서 $DATA 속성에 관한 Resident, Non-resident 속성과 Cluster Run에 대해서는 위에서 언급을 했으니 다시 찾아보도록 하자!
$DATA 속성은 이름에서도 알 수 있듯이 파일의 데이터를 저장하는 속성이다. 일반적으로 700Byte보다 크다면 Non-resident 속성에 저장되므로 MFT 엔트리가 아닌 파일시스템 데이터 영역에 별도로 클러스터를 할당 받아 저장하게 된다. 하지만 700Byte보다 적을 경우 Resident 속성이 되어 MFT 엔트리 내부에 데이터가 저장하게 된다. 하지만 700 Byte의 크기가 고정적으로 정해져 있는 것이 아니다. 왜냐하면 MFT 엔트리의 크기는 1,024 Byte인데 여기서 기본 속성을 가지는 파일일 경우 MFT 엔트리 헤더, $STANDARE_INFORMATION, $FILE_NAME 속성을 제외하면 약 700 Byte가 남는데 저 두 속성은 가변적이기 때문에 항상 700Byte라고 하는 것은 무리가 있다.
$DATA 속성의 구조를 한번 보겠습니다.

$DATA에 해당하는 예시를 보겠습니다.

$DATA 속성에 포함되어 있는 정보를 보겠습니다.

대부분 Cluster Run 형식으로 저장된다.
Attribute - $INDEX_ROOT (0x90)
$INDEX_ROOT는 속성 식별 값 0x90을 가지는 속성입니다. 이 속성 값은 앞에 다른 속성들과는 좀 다르게 인덱스를 담고 있는 부분이기 때문에 많이 복잡한 구조를 가지고 있습니다.
인덱스의 맨 꼭지점인 루트에 해당하는 인덱스 노드를 담는 속성으로, NTFS는 인덱스 크기가 작으면 $INDEX_ROOT 속성만으로 인덱스를 구성합니다. 해당 속성은 Non-resident가 아닌 Resident 형식을 이용하기 때문에 많은 Index 엔트리를 담지 못합니다.
그렇기 때문에 많은 Index 엔트리를 사용해야 한다면 $INDEX_ALLOCATION 속성을 만들어서 관리를 해야 합니다.
$INDEX_ALLOCATION 속성이 사용된다면 Index Record의 할당을 관리 하기 위한 $BITMAP 속성도 같이 생성되어야 합니다.
많이 어려우시더라도 최대한 쉽게 설명을 하기 위해서 노력하겠습니다.
먼저, $INDEX_ROOT의 구조를 보겠습니다.

가장 기본 기본적으로 따라오는 Attribute Header 다음에 Index Root Header, Index Node Header와 여러 개의 Index Entry, 마지막으로 End of Node가 같이 나옵니다.
위 간단한 구조를 자세히 살펴보도록 하겠습니다.

$INDEX_ROOT에 해당하는 예시를 한번 보겠습니다.

엄청 많은 양의 데이터를 가지고 있기 때문에 지금 보여주는 표를 한번 실습해보면서 따라 가보도록 하겠습니다.

Collation Sorting Rule에 들어있는 값에 대한 정보를 보겠습니다.

다음은 Index Node Header Flags에 들어있는 값에 대한 정보를 보겠습니다.

마지막으로 Index Entry Flags에 들어있는 값에 대한 정보를 보겠습니다.

위의 예시 데이터를 가지고 $INDEX_ROOT의 구조에 따라 정리를 한번 해보겠습니다.
참고로, 빨간색으로 블록된 부분으로 Address Range를 계산하여 표를 만들었으니 무조건 시작점은 0x00으로 지정을 해놨습니다. 읽으실 때, 오해를 하지 않으셨으면 좋겠습니다.
1-1. Attribute Header (0xA9ACD00 ~ 0xA9ACD1F : 32Byte)

위에 나와 있는 hxd 값을 가지고 표를 만들어봤습니다.

1-2. Index Record Header (0xA9ACD20 ~ 0xA9ACD2F : 16Byte)

위에 나와 있는 hxd 값으로 표를 만들어봤습니다.

1-3. Index Node Header (0xA9ACD30 ~ 0xA9ACD3F : 16Byte)

위에 나와 있는 hxd 값으로 표를 만들어봤습니다.

1-4. Index Entry 1 (0xA9ACD40 ~ 0xA9ACDA7 : 104Byte)

위에 나와 있는 hxd 값으로 표를 만들어봤습니다.

이 표를 보면 Address Range를 봐도 이상하고 Filed Name도 처음엔 이해가 안되실 수 있습니다. 그래서 왜 이런 표를 구성했는지 간단하게 설명을 좀 드리자면 위 Index Entry 1의 구조를 보면 File Reference Address for Filename부터 시작을 하시는 것 까지는 이해를 하셨을 거라 생각이 듭니다. Flags까지는 구조를 따라서 갈 수 있습니다. 하지만 그 밑에 File Reference Address of Parent Directory 이 부분부터는 좀 이해가 안되실거라 생각이 듭니다. 그래서 Index Entry 구조를 보시면 Flags 이후에 $FILE_NAME Attribute라고 적혀있는데 이게 $FILE_NAME Attribute 구조에 따라서 분석을 진행해라. 이런 느낌입니다. 지금 예시에 있는 35 37 DF 91 92 BE D8 01 로 된 부분이 있을겁니다. 이건 MAC Time을 나타내는 부분입니다. 이 부분에 대해서는 생략을 진행하였고, 중요한 필드만 가져왔습니다.
1-5. Index Entry 2 (0xA9ACDA8 ~ 0xA9ACE07 : 96Byte)

위에 나와 있는 hxd 값으로 표를 만들어 봤습니다.

1-6. Index Entry 3 ( 0xA9ACE08 ~ 0xA9ACE67 : 96Byte)

위에 나와 있는 hxd 값으로 표를 만들어봤습니다.

1-7. Index Entry 4 (0xA9ACE68 ~ 0xA9ACECF : 104Byte)

위에 나와 있는 hxd 값으로 표를 만들어봤습니다.

1-8. Index Entry 5 (0xA9ACED0 ~ 0xA9ACF37 : 104Byte)

위에 나와 있는 hxd 값으로 표를 만들어봤습니다.

그리고 최종적으로 위의 값에 보시면 0xFFFFFFFF가 나오는 것을 확인할 수 있는데, 이 부분은 End of Node를 뜻하는 부분입니다.
Attribute - $INDEX_ALLOCATION (0xA0)
$INDEX_ALLOCATION은 속성 식별 값 0xA0을 가지는 속성입니다.
$INDEX_ALLOCATION 속성이 추가 되면 $BITMAP 속성도 같이 따라오게 되는데, 이때 $INDEX_ALLOCATION 속성을 관리하는 Index Record 2개가 클러스터를 할당 받아 새로 생성되며 그 안에 Root Index Entry를 가지게 됩니다. 그리고 언제나 Non-Resident 형식을 가지고 있으며 크기 또한 제한이 없습니다. 마지막으로 $BITMAP 속성의 경우 각각의 bit 들은 Index Record 들과 1대1 대응합니다.
$INDEX_ALLOCATION의 구조를 보겠습니다.

기본적으로 속성 값에 따라오는 Attribure Header 다음에 Index Root Header가 아닌 Index Record Header가 나오고, Index Node Header, 여러개의 Index Entry, 마지막으로 End of Node가 나옵니다.
자세한 구조를 한번 보겠습니다.

$INDEX_ALLOCATION에 해당하는 예시를 보겠습니다.
일단 이 $INDEX_ALLOCATION에 해당하는 예시를 보기전에, 찾아가는 방법을 알아야 합니다.
$I30 파일은 INDX 파일로 각 파일에 대한 레코드를 포함한 파일로써 각각의 루트 디렉터리에 존재하는 파일들에 대한 인덱스 데이터가 담겨있습니다. 그래서 MFT Entry의 예약된 번호를 보면 5번에 Root Directory가 존재하는데 Record Number가 5번이기 때문에 계산을 하면 다음과 같습니다.
MFT 섹터(347,472) + 5 * 2 = 347,482 섹터로 가시면 볼 수 있습니다.

각 정보들을 한번 보겠습니다.

$INDE_ROOT에서 언급을 하였듯이 Index Entry가 많거나 데이터가 크면 $INDEX_ROOT가 아닌 $INDEX_ALLOCATION을 이용하여 Cluster Run을 이용하여 데이터를 저장한다고 했었습니다.
위 예시에서 마지막에 보이는 11 01 24이 클러스터 런을 가르키고 있습니다.
클러스터 런에서 보면 Data Run Length와 Data Run Offset이 있는데, 이 오프셋 부분이 0x24이므로, 36섹터 * 8섹터 = 288 섹터에 위치합니다.

위 예시를 가지고 정리를 한번 해보겠습니다.
1-1. Attribute Header (0xA9AB658 ~ 0xA9AB6A7 : 80Byte)

위에 나와 있는 hxd 값으로 표를 만들어봤습니다.

1-2. Index Record Header (0x24000 ~ 0x24017 : 24Byte)

위에 나와 있는 hxd 값으로 표를 만들어 봤습니다.

1-3. Index Node Header (0x24018 ~ 0x24027 : 16Byte)

위에 나와 있는 hxd 값으로 표를 만들어 봤습니다.

1-4. Index Entry 1 (0x24058 ~ 0x240BF : 104Byte)

위에 나와 있는 hxd 값으로 표를 만들어 보겠습니다.

1-5. Index Entry 2 (0x240C0 ~ 0x24127 : 104Byte)

위에 나와 있는 hxd 값으로 표를 만들어 보겠습니다.

1-6. Index Entry 3 (0x24128 ~ 0x24187 : 96Byte)

위에 나와 있는 hxd 값으로 표를 만들어 보겠습니다.

1-7. Index Entry 4 (0x24188 ~ 0x241E7 : 96Byte)

위에 나와 있는 hxd 값으로 표를 만들어 보겠습니다.

1-8. Index Entry 5 (0x241E8 ~ 0x24247 : 96Byte)

위에 나와 있는 hxd 값으로 표를 만들어 보겠습니다.

1-9. Index Entry 6 (0x24248 ~ 0x242AF : 104Byte)

위에 나와 있는 hxd 값으로 표를 만들어 보겠습니다.
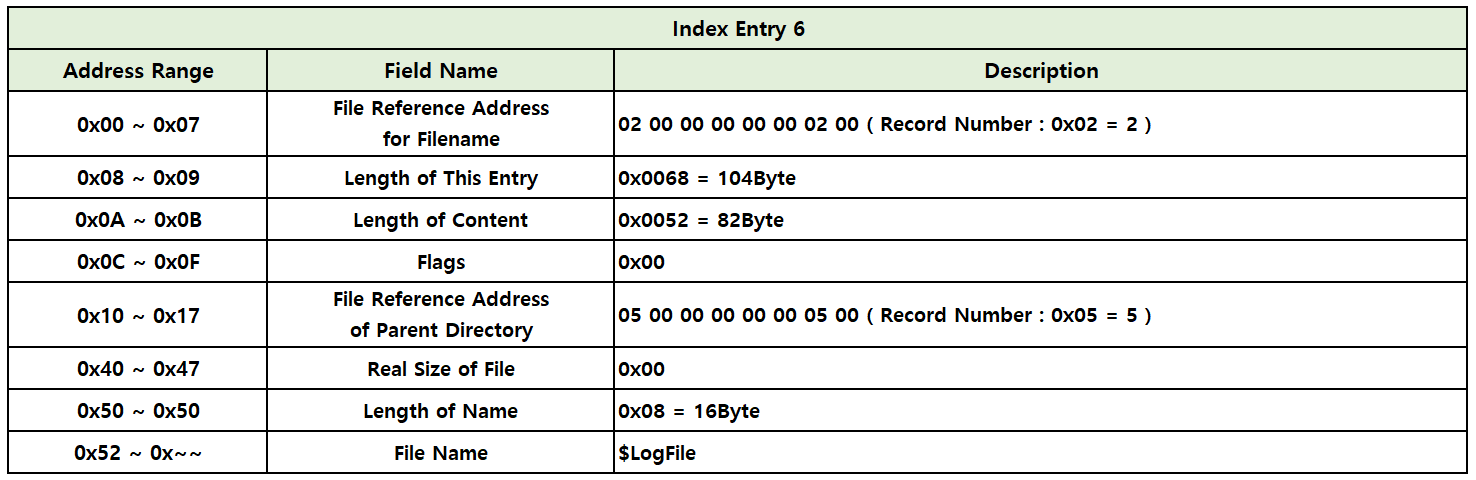
1-10. Index Entry 7 (0x242B0 ~ 0x2430F : 96Byte)

위에 나와 있는 hxd 값으로 표를 만들어 보겠습니다.

1-11. Index Entry 8 (0x24310 ~ 0x24377 : 104Byte)

위에 나와 있는 hxd 값으로 표를 만들어 보겠습니다.

1-12. Index Entry 9 (0x24378 ~ 0x243E7 : 106Byte)

위에 나와 있는 hxd 값으로 표를 만들어 보겠습니다.

1-13. Index Entry 10 (0x243E8 ~ 0x24447 : 96Byte)

위에 나와 있는 hxd 값으로 표를 만들어 보겠습니다.

1-14. Index Entry 11 (0x24448 ~ 0x244A7 : 96Byte)

위에 나와 있는 hxd 값으로 표를 만들어 보겠습니다.

1-15. Index Entry 12 (0x244A8 ~ 0x24507 : 96Byte)

위에 나와 있는 hxd 값으로 표를 만들어 보겠습니다.

1-16. Index Entry 13 (0x24508 ~ 0x2455F : 94Byte)

위에 나와 있는 hxd 값으로 표를 만들어 보겠습니다.

1-17. Index Entry 14 (0x24560 ~ 0x245E7 : 136Byte)

위에 나와 있는 hxd 값으로 표를 만들어 보겠습니다.

마지막으로 INDX 시그니처를 가지고 있는 파일들이 많이 존재 하는데 각 파일의 종류와 설명을 보겠습니다.

$I30을 제외한 나머지의 INDEX 파일들은 메타 데이터 파일로 기본적인 $INDEX_ALLOCATION 구조와는 차이가 있습니다.
Attribute - $BITMAP (0xB0)
$BITMAP은 속성 식별 값 0xB0을 가지는 속성입니다.
NTFS에는 할당 정보를 관리 해야 하는 데이터들이 많이 있는데, 이 중 MFT와 Index의 할당 정보를 관리 하는데 사용하는 속성입니다.
클러스터의 할당 정보를 관리하는 $BITMAP 메타 데이터 파일
할당 정보를 관리 하는 데이터 : $MFT, $INDEX_ALLOCATION
$BITMAP 구조를 한번 보겠습니다.

예시를 한번 보겠습니다.

위 hxd 값을 보면 Cluster Run 데이터가 1개가 있습니다.

0x0589 = 1,417 * 8 = 11,336 섹터에 가면 데이터가 하나 존재합니다.

MFT Entry 할당 상태를 확인해 볼 수 있습니다.
- 0번 오프셋(FF) -> 1111 1111 (MFT Entry 0 ~ 7 할당)
- 1번 오프셋(FF) -> 1111 1111 (MFT Entry 8 ~ 15 할당)
- 2번 오프셋 (00) -> 0000 0000 (MFT Entry 16 ~ 23 비할당)
- 3번 오프셋 (FF) -> 1111 1111 (MFT Entry 24 ~ 31 할당)
- 4번 오프셋 (FF) -> 1111 1111 (MFT Entry 32 ~ 39 할당)
- 5번 오프셋 (FF) -> 1111 1111 (MFT Entry 40 ~ 47 할당)
- 6번 오프셋 (3F) -> 0011 1111 (MFT Entry 48, 49, 50, 51, 52, 53 할당 , 54, 55 비할당)
- 7번 오프셋 (00) -> 0000 0000 (MFT Entry 56 ~ 63 비할당)
Attribute - $REPARSE_POINT (0xC0)
$REPARSE_POINT는 속성 식별 값 0xC0을 가지는 속성입니다.
NTFS 5.0 버전 이후로 생성된 속성으로 이전 버전에는 $SYMBOLIC_LINK라는 속성이 존재했습니다.
해당 속성은 마운트, 잭션, 심볼릭 링크에 대한 정보를 담고 있습니다.
$REPARSE_POINT의 구조를 보겠습니다.

자세한 내용을 보겠습니다.

마지막으로 0x00 ~ 0x03 필드에 들어가는 Flag 값만 보고 포스팅을 마치도록 하겠습니다.

여기까지 MFT 구조에 대한 포스팅을 마치도록 하겠습니다...지금 배우는 것도 힘든데 예전에 배우신 분들 존경합니다 ㅜㅜㅜ
-Reference-
https://docs.microsoft.com/ko-kr/troubleshoot/windows-server/backup-and-storage/ntfs-reserves-space-for-mft
https://ws1004-4n6.notion.site/MFT-File-System-Structure-Analysis-24a7386dae0246758173188eaba5bd2f#d3ae326f394a49ebb16dcfa09f2841a4
http://forensic-proof.com/archives/584
https://piki-play.tistory.com/44
http://ayoungkh.blogspot.com/2019/01/2019-01-04-nfts.html