이번에 연구를 진행했던 포렌식은 웹 브라우저 포렌식에 관한 내용인데, 정리를 하고자 작성을 시작했습니다.
1. 개요
웹 브라우저 분석을 진행하게 된 이유는 포렌식 관점에서 매우 중요하기 때문입니다. 그 이유는 사용자들이 자주 사용하는 웹 브라우저의 아티팩트를 분석할 경우 사용자의 관심사 또는 범죄 사건에 필요한 각종 단서(URL, 자주 검색한 키워드, 다운로드) 등을 파악할 수 있습니다.
침해사고 분석 시에도 웹 브라우저를 분석하는 것은 중요합니다. 왜냐면 악성 파일의 유입 경로가 사용자들이 크랙버전을 다운 받거나 악성코드가 심어져있는 악성 문서가 메일로와서 다운을 받게 됩니다. 이때 다운받은 파일들의 경로들이 웹 브라우저 로그에 저장되어 있으니 악성 코드 감염 유입 경로를 파악할 수 있는 정보를 얻을 수 있다. 하지만 현실적으로 웹 브라우저 아티팩트를 통해서 나온 증거들이 직접 증거로 채택되는 것이 어렵지만 사건 해석에 대한 정황 증거로서는 매우 유용하게 활용될 수 있기 때문에 분석을 진행하게 되었습니다.
2. 아티팩트
먼저, 아티팩트라는 단어에 대해서 포렌식을 하시는 사람들도 처음에는 아마 어렵게 느껴지던 단어일 것입니다. 설명을 드리자면 아티팩트를 해석을 해보면 "인공물, 흔적" 이라고 볼 수 있습니다. 결국엔 컴퓨터 시스템에서 사용자가 어떠한 행위를 했을 때, 운영체제가 이벤트 로그를 남기든 데이터 로그를 남기든 특정한 행위에 대한 활동 흔적을 남기는데 이런 사용 활동 흔적을 흔히 아티팩트라고 말합니다.
3. 분석 브라우저
제가 분석을 진행한 브라우저는 총 3개로 Microsoft Edge, Chrome, Naver Whale입니다. 이 3개의 브라우저를 분석 진행한 이유는 다음과 같습니다.
Microsoft Edge
- Windows10 사용자라면 기본적으로 제공되는 웹 브라우저
- 2020년 브라우저 버전을 레거시에서 크롬, 웨일과 같은 크로미엄 오픈 소스를 기반으로 바꾼 신 버전 출시
Chrome
- 구글이 개발한 크로미엄 오픈 소스를 기반으로 만들어진 웹 브라우저- 전 세계에서 사용자들이 가장 많이 사용
Naver Whale
- 한국에서 가장 많은 비율을 차지하고 있는 포털사이트인 네이버가 출시- Chrome과 동일하게 크로미엄 오픈 소스를 기반으로 만들어진 웹 브라우저
4. 일반 모드 아티팩트 분석
일반 모드 아티팩트라 함은 우리가 웹 브라우저를 이용할 때 2가지의 모드를 제공합니다. 바로가기 아이콘을 눌렀을 때 실행되는 모드는 일반 모드이고 우측 상단에 ...을 눌러서 "새 시크릿 창" 또는 "새 Inprivate 창" 라는 문구를 클릭하면 다음과 같이 새로운 웹 브라우저가 실행 됩니다.

이렇게 시크릿 모드가 아닌 모드를 일반 모드라고 칭하며 바로 분석을 같이 해보겠습니다.
4.1 Microsoft Edge
먼저, 마이크로소프트 엣지는 활동 데이터들이 WebCacheV01.dat 파일에 저장되어 있기 때문에 다음과 같은 경로에서 파일을 추출해야 합니다.
경로 : C:\Users\{User}\AppData\Local\Microsoft\Windows\WebCache
WebCacheV01.dat 파일은 ESE(Extensible Storage Engin) Database Format 파일 구조로 되어 있으며, 다른 파일과는 다르게 위 경로에서 바로 분석이 불가능 합니다. 분석이 불가능 한 이유는 WebCacheV01.dat 파일을 읽기 접근을 할려고 할 때 다른 프로세스가 파일을 사용 중이기 때문에 프로세스가 엑세스 할 수 없다고 뜹니다. 그리고 WebCacheV01.dat 파일에 저장되는 정보들로는 History, Cache, Cookies, Download 들이 있습니다.

WebCacheV01.dat 파일을 수집하기 위해서는 다음과 같은 방법을 사용합니다.
단, 현장에 나가서 수집을 할 때는 밑에 방법과 동일하게 하면 시스템을 건들이는 행위가 되기 때문에 무결성이 훼손됩니다. 그래서 현장에서는 포렌식 도구들을 활용해 쓰기 방지를 하고 이미징을 떠서 수집을 합니다.
• cmd를 관리자로 실행
• tasklist | find /i “taskhost” (실행중인 프로세스 찾기)
• taskkill /f /im “<프로세스명>” /t (실행중인 프로세스 종료)
• xcopy /s /h /i /y “%Localappdata%\Microsoft\Windows\Webcache\*.dat” <경로> (복사)
• esentutl /mh <복사한 경로>WebCacheV01.dat (상태 확인)
• esentutl /p <복사한 경로>WebCacheV01.dat
수집이 완료 되었으면, ESEDataBaseView 프로그램으로 파일을 열어볼 수 있습니다.
ESEDataBaseView 프로그램은 ESEDataBase Format으로 작성되어 있는 파일을 분석하는 프로그램으로써, 각 정보들이 Container_N 형식의 이름을 가진 테이블에 저장이 됩니다.

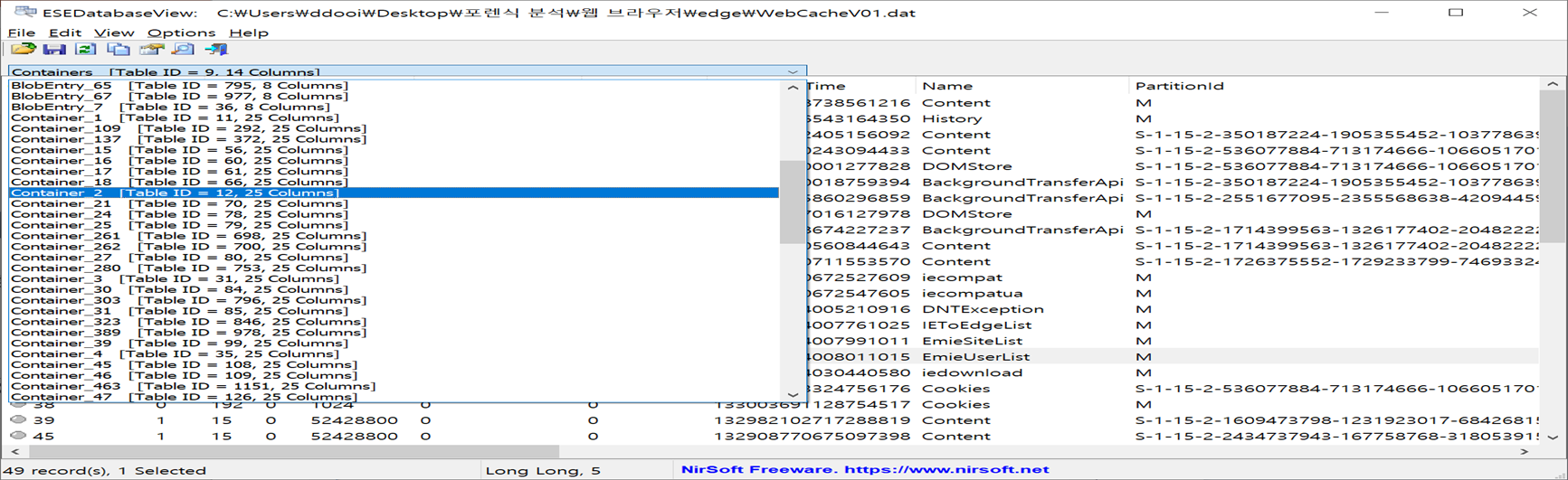
그리고 가장 중요시 봐야하는 부분이 ContainerID 칼럼과 Name 칼럼인데, 두 개를 참조하여 데이터가 저장되는 테이블을 찾아가야 하기 때문입니다.
위 그림을 보시면 ContainerID가 2번인 레코드의 Name이 History입니다.
그래서 아래쪽 그림을 보면 Container_2번 테이블을 가르키고 있는 것을 볼 수 있는데, 해당 테이블에 가면 History 정보들을 확인할 수 있었습니다.
4.1.1 History
History는 ESEDataBaseView에서 Name값이 "History" 와 "MSHist01~" 입니다. 저장되는 정보로는 사용자가 방문한 웹 사이트의 접속 정보와 사용자의 편의를 위해 (다시 방문, 월별/일별 방문 기록) 저장됩니다.
프로그램에서 파싱해주는 주요 정보를 한번 보겠습니다.

- Accessed Time(접근 시간) : 해당 History 접근 시간
- Sync Time(동기화 시간) : Access Time과 동일
- Creation Time(생성 시간) : 항상 0값을 가짐
- Expiry Time(만료 시간) : 해당 History 데이터 만료 시간, 만료 후 레코드 삭제 (기본 20일)
- Modified Time(수정 시간) : Access Time과 동일
- URL : URL 정보를 담고 있으며, Visited <사용자명>@http 형식
- ResponseHeader : 웹 페이지 제목 정보가 들어있는 데이터가 저장
4.1.2 Cache
Cache는 웹 사이트 접속 시 방문했던 사이트로부터 데이터를 자동으로 다운받은 것, 재접속 시 다시 다운 받지 않고 다운 받은 데이터를 사용하여 웹 페이지의 로딩을 빠르게 해준다거나 하는데 쉽게 데이터를 미리 저장해놨다가 사이트를 방문하게 되면 미리 저장해둔 값으로 바로 연결시켜주는 값입니다.

Cache는 Cache 데이터와 Cache 인덱스 정보로 구분되는데, Cache 데이터는 실제로 저장되어 있는 Cache의 데이터를 의미하고 Cache 인덱스 정보는 저장되어 있는 Cache 값의 위치를 알려주는 것입니다. (나중에 Chrome 설명할 때 나옴)
History와 마찬가지로 Containers_N 형식으로 되어 있는데, Name값이 "Content" 인 값이 캐시 데이터를 저장하고 있는 테이블입니다.

파싱해준 값으로 봤을 때, 중요한 부분은 UrlHash부분과 Url 부분인데, lettoknow.com이라는 사이트에 여러번 접속한 것을 확인할 수 있었는데 Url이 비슷하니까 UrlHash값도 앞부분이 똑같다는 것을 확인할 수 있었습니다.
이 특징을 봤을 때, Url이 없더라도 UrlHash을 보고 같은 사이트에 접속한 내역을 확인할 수 있습니다.
Cache 데이터도 마찬가지로 주요 정보를 보겠습니다.
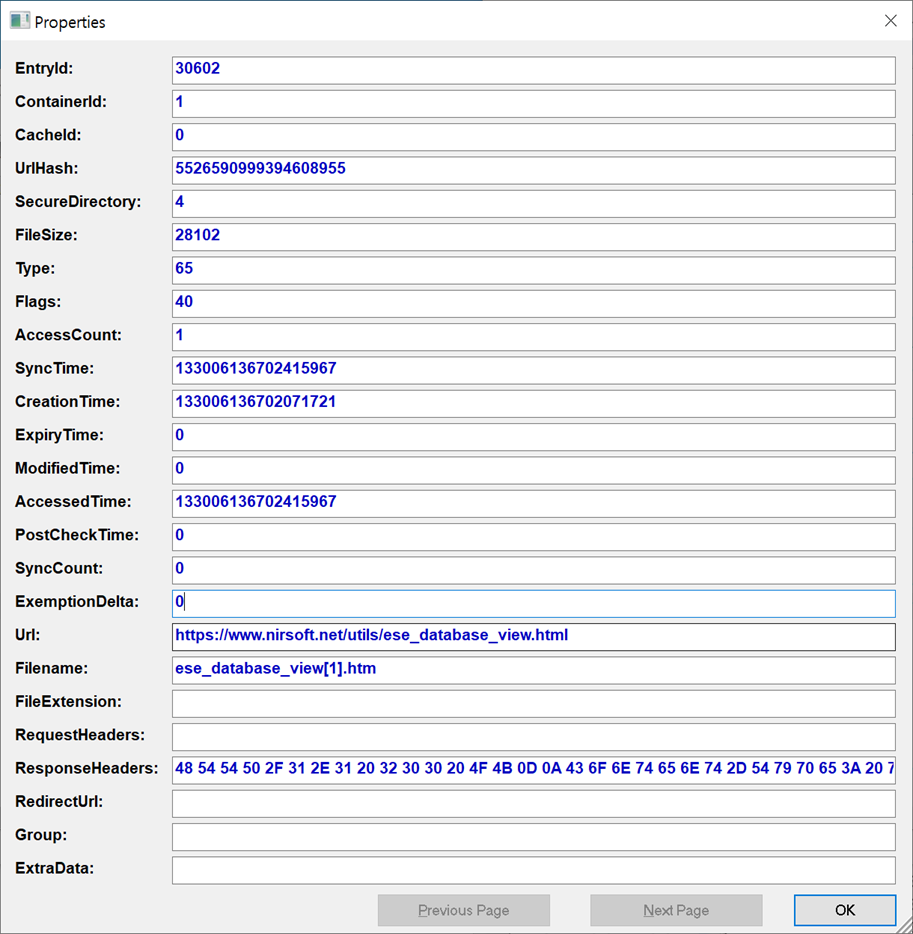
- Access Time : 해당 사이트 접근 시간 or 해당 파일 열람 시간 (FILETIME을 10진수로 변환)
- Sync Time : Access Time과 동일
- Creation Time : 항상 0 값을 가짐
- Expiry Time : 해당 Cache 데이터 만료 시간, 만료 후 레코드 삭제 (기본 20일 후)
- Modified Time : Access Time과 동일
- URL : 해당 Cache 데이터를 다운로드 한 URL
- Filename : Cache 데이터 파일명
- Filesize : Cache 데이터 크기
- ResponseHeaders : 웹 페이지 제목 정보가 들어있는 데이터 저장 (Hex 값)
- SecureDirectory : 해당 Cache 데이터가 저장되어 있는 폴더의 인덱스 정보
4.1.3 Cookies
Cookies는 웹 사이트에서 사용자의 하드디스크에 저장 시켜 놓은 사용자에 관한 데이터와 사용자 별, 개인화된 서비스 제공을 위해 사용됩니다. 예로 자동 로그인이 쿠키값에 해당됩니다.

Cookies값도 Containers_N 형식으로 되어 있는데 Name 값이 Cookies입니다.
Cookies의 주요 정보는 다음과 같습니다.
- Access Time : 해당 사이트 접근 시간 or 해당 파일 열람 시간 (FILETIME을 10진수로 변환)
- Sync Time : Access Time과 동일
- Creation Time : 항상 0 값을 가짐
- Expiry Time : 해당 Cookies 데이터 만료 시간, 만료 후 레코드 삭제 (기본 20일 후)
- Modified Time : Access Time과 동일
- Url : 해당 Cookies의 호스트 정보
- Filename : 실제 쿠키 정보를 저장하고 있는 쿠키 파일의 이름 ( 경로는 Containers 테이블의 Directory에서 확인 )

저 같은 경우는 Edge 브라우저를 사용하지 않아서 저장되어 있는 Cookies값이 없어 경로를 찾아 가봤지만 역시나 0byte임을 확인할 수 있었습니다.
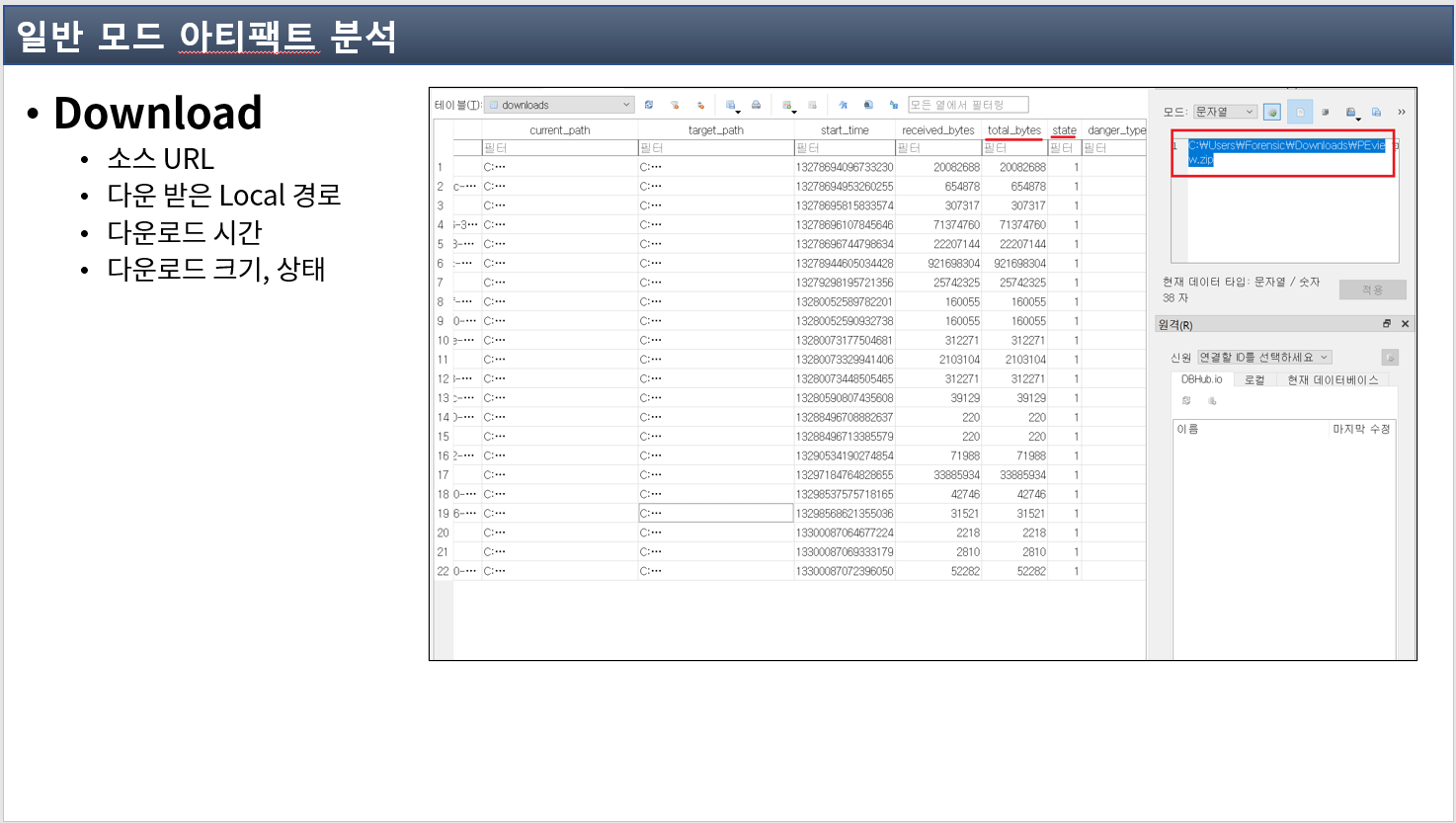
4.1.4 Download
Download는 사용자가 의도적으로 자신의 컴퓨터로 내려 받은 파일에 대한 정보를 담고 있습니다.

Download 값도 Containers_N 형식으로 되어 있는데 Name 값이 ieDownload입니다.
Download의 주요 정보는 다음과 같습니다.
- Access Time : 다운로드 시간 (FILETIME을 10진수로 변환)
- Sync Time : Access Time과 동일
- Creation Time : 항상 0 값을 가짐
- Expiry Time : 항상 0 값을 가짐
- Modified Time : 항상 0 값을 가짐
- Url : 다운로드 GUID 값 저장
- ResponseHeader : 소스 URL, 저장 경로 정보가 들어 있는 데이터가 저장
여기까지 마이크로소프트 엣지 브라우저를 분석했습니다.
다음은 Chrome과 Naver Whale에 대한 분석인데 두 브라우저 모두 크로미엄 오픈소스를 기반으로 만들어진 웹 브라우저이기 때문에 같은 방식으로 분석을 진행 하시면 됩니다. 그럼 바로 시작하겠습니다.
4.2 Chrome & Whale
Chrome & Whale 아티팩트 경로
History
•C:\Users\{User}\AppData\Local\Google\Chrome\User Data\Default\History
•C:\Users\{User}\AppData\Local\Naver\Naver Whale\User Data\Default\History
Cache
•C:\Users\{User}\AppData\Local\Google\Chrome\User Data\Default\Cache\Cache_Data
•C:\Users\{User}\AppData\Local\Naver\Naver Whale\User Data\Default\Cache\Cache_data
Cookies
•C:\Users\{User}\AppData\Local\Google\Chrome\User Data\Default\Network\Cookies
•C:\Users\{User}\AppData\Local\Naver\Naver Whale\User Data\Default\Network\Cookies
Download
•C:\Users\{User}\AppData\Local\Google\Chrome\User Data\Default\History
•C:\Users\{User}\AppData\Local\Naver\Naver Whale\User Data\Default\History
4.2.1 History
크롬과 웨일은 엣지 브라우저와는 다르게 History가 하나의 파일로 생성되어 있습니다. 그리고 ESE 데이터베이스 포맷 구조가 아닌 SQL 데이터베이스 포맷 구조로 되어있어 DB Browser for SQLite 프로그램을 사용해서 파싱을 하였습니다.
History에 들어있는 주요 정보들은 다음과 같습니다.
- URL : 웹 사이트 방문 URL
- Downloads : 다운로드 정보
- Keyword_search_terms : 자주 입력한 검색에 대한 키워드
- Visits : 실제 방문 정보 저장
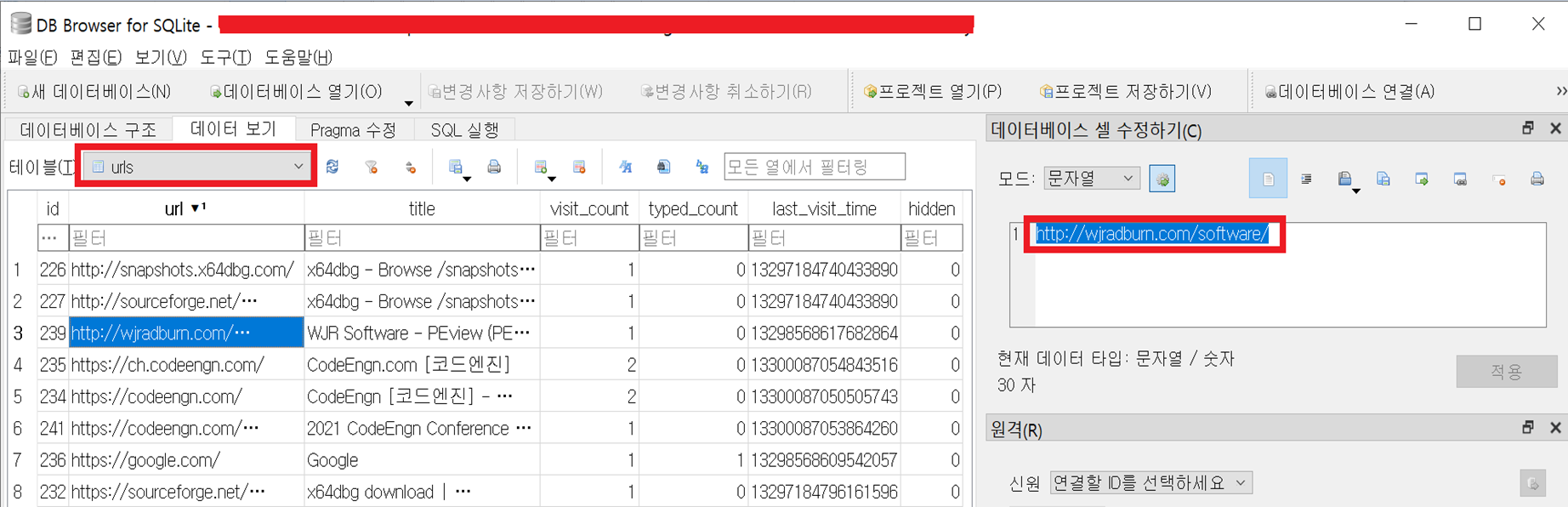
아래 그림은 URL 테이블을 가져왔는데, 코드엔진을 이용했던 URL과 PEView를 다운받기 위해 들어간 URL 등을 확인할 수 있었습니다.
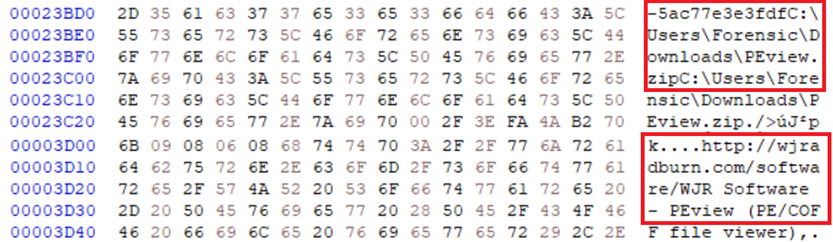
그리고 파싱된 값과 Hex 에디터를 열었을 때 값을 비교하여 동일한 값을 가지고 있다는 것을 확인할 수 있었습니다.
4.2.2 Cache
아마 제가 분석한 부분 중 가장 많은 내용을 다루지 않을까 싶습니다. 하나씩 차례대로 수동으로 캐시 데이터의 값을 찾는 방법을 알아볼테니 실습을 해보시길 바랍니다. 바로 시작하겠습니다.

먼저, 크롬과 웨일은 캐시 데이터가 위 사진과 같이 파일로써 남습니다.
내용이 조금 어렵기 때문에 각 파일에 대해서 설명을 풀어서(?) 쓰겠습니다.
data_0의 파일을 보면 다른 data_N 형식의 파일보다 용량이 적은것을 확인할 수 있는데, 이 파일에 저장되는 것은 다른 data_1, data_2, data_3에 저장되는 값이랑 조금 다르기 때문입니다.
data_0에는 캐시 데이터의 인덱스 레코드가 저장이 되는데, 쉽게 말해서 캐시 데이터가 저장된 URL의 위치를 표현하는 값들이 저장되어 있다고 보시면 됩니다.
data_1, data_2, data_3 파일은 data_0에서 찾은 캐시 데이터들이 실제로 어떤 값을 가지고 있는지 보여주는 캐시 데이터를 저장하는 파일입니다.
f_000~로 저장되는 파일은 위 data_1, data_2, data_3 파일에 들어있는 캐시 데이터의 용량이 클 경우 따로 파일이 하나 생성이 되어 f_000~에 저장이 됩니다. 그러니까 만약 1KB인 캐시 데이터는 data_1, data_2, data_3에 저장이 되지만 100KB가 되는 캐시 데이터는 따로 f_000~ 이름을 가지고 따로 파일이 하나 생성된다고 생각 하시면 됩니다.
이렇게 각 파일에 대해서 설명을 드렸고, 캐시 데이터를 찾아가는 방법을 공부하겠습니다.
* Cache 정보 분석 *
먼저, Cache 정보를 분석하기 전에 data_0 파일에 대해서 보면 data_0 파일은 인덱스 레코드를 저장한다고 했는데, 파일의 구조는 하단에 그림과 같이 구성되어 있습니다.

파일 구조를 보면 0x18 ~ 0x2B인 4바이트만큼 URL 레코드 위치 정보를 표시한다고 되어있습니다.
또 다른 특징은 data_0는 오프셋이 0x2000(8192byte)부터 0x24(36byte) 단위로 저장이 됩니다.
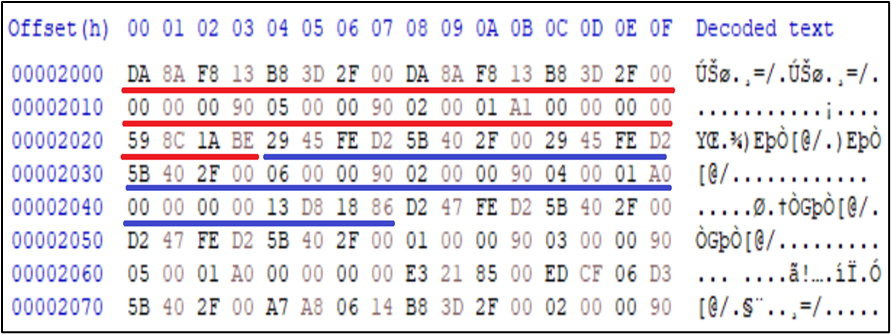
예시로 보면 16진수로 24값만큼 표시를 해놨습니다.

그리고 이 4바이트가 URL 레코드 위치 정보가 됩니다.
다음 알고 있어야 되는 지식은 data_1, data_2, data_3가 캐시 데이터를 저장한다고 했는데, 마찬가지로 이 파일들도 오프셋 0x2000부터 "블록 단위"로 URL(레코드), 메타 데이터, 캐시 데이터를 저장한다는 것입니다.
그리고 블록 단위라는 것은 파일이 저장되는 단위? 라고 생각을 하시면 되는데 이 부분을 파악할려면 위 URL 레코드 위치 정보를 보면 파악할 수 있지만 조금 있다가 설명을 드리고, 블록 단위의 수치를 보시면 각 파일마다 표현하는 값이 다름을 알 수 있습니다.
< 블록 단위 >
data_1 = 0x100 (0x01)
data_2 = 0x400 (0x02)
data_3 = 0x1000 (0x03)
여기까지 정리를 해보면, 캐시 데이터에는 인덱스 레코드를 저장하는 data_0파일과 캐시 데이터를 저장하는 data_1, data_2, data_3 파일이 존재하고, 캐시 데이터가 클 경우 f_000~과 같은 파일로 저장이된다. 그리고 data_0 파일은 오프셋 0x2000부터 시작되며 0x24(36byte)만큼 짤라서 보면 된다. 그리고 data_1, data_2, data_3 파일도 마찬 가지로 오프셋 0x2000부터 시작을 하지만 "블록 단위" 라는 것에 의해서 오프셋이 결정이 됩니다.
분석을 이어 나가겠습니다.
위 이론적인 부분을 이해를 하셨으면 이제 URL 레코드 포맷 구조를 보겠습니다.
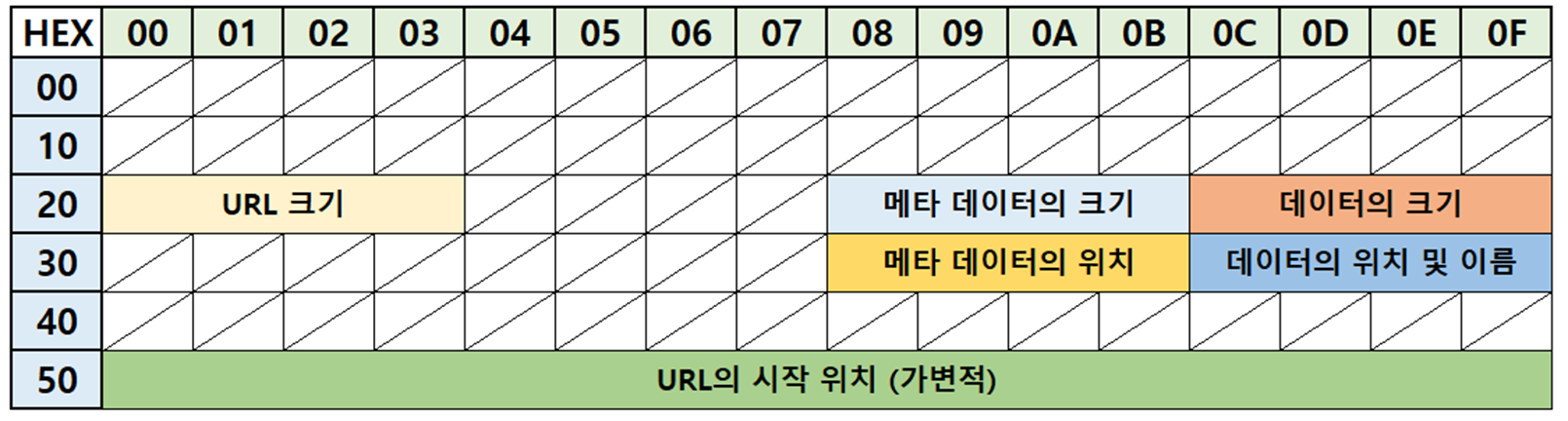
URL 레코드 포맷 구조는 data_0 파일에서 URL 레코드 위치 정보를 토대로 캐시 데이터가 존재하는 오프셋을 찾아갔을 때 볼 수 있는 구조입니다. 구성은 다음과 같습니다.
<URL 레코드 포맷 구조>
0x20 ~ 0x23 = 4바이트 (URL 크기)
0x28 ~ 0x2B = 4바이트 (메타 데이터의 크기)
0x2C ~ 0x2F = 4바이트 (데이터의 크기)
0x38 ~ 0x3B = 4바이트 (메타 데이터의 위치)
0x3C ~ 0x3F = 4바이트 (데이터의 위치 및 파일 이름)
0x50 ~ = (URL의 시작 위치)
여기까지 이해를 하시면 정말 다 된겁니다. 이제 예제로 데이터를 찾아 가보겠습니다.

위 사진은 data_0 파일의 오프셋 0x2000부분이며, 빨간색으로 표시된 부분은 URL 레코드 위치 정보입니다.
이 4바이트를 계산하는 방식은 다음과 같습니다.
* 4Byte중 2번째 Byte까지 *
- 블록의 인덱스
- 0x0001이면 두번째 블록에 URL 레코드가 저장
* 4Byte중 3번째 Byte는 파일의 인덱스 *
- 0x01이면 data_1, 0x02이면 data_2, 0x03이면 data_3 파일에 URL 레코드 정보 저장
* URL 레코드 위치 계산 *
- 블록의 인덱스 * 블록 단위 + 0x2000
텍스트로만 보면 이해가 안되실거니까 바로 계산을 해보겠습니다.
위 사각형을 가져오면 02 00 01 A1 입니다. 이 중 블록의 인덱스는 02 00 입니다. 그리고 파일의 인덱스는 01 입니다.
리틀 엔디안으로 계산을 하면 다음과 같습니다.
- 블록의 인덱스 = 0x0002
- 파일의 인덱스 = 0x01 = data_1
- URL 레코드 위치 계산 = 0x0002 * 0x100 + 0x2000 = 0x2200 오프셋
정리를 하면 URL 레코드 위치 계산에서 나온 0x2200 오프셋에 위에 있는 예시 캐시 데이터가 저장이 되어있고! 저장이 되어있는 파일은 data_1이다. 라고 생각을 하시면 됩니다.
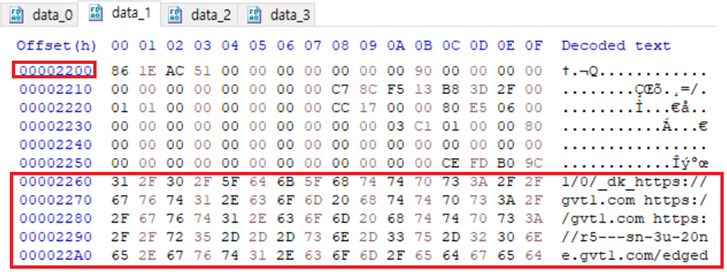
이렇게 data_1 파일에 0x2200 오프셋에 데이터가 있고 0x2260부터 URL을 볼 수 있는 것을 알 수 있습니다!!
요기까지 찾아왔으면 진짜 잘한겁니다. 그 다음에 이제 URL 레코드 포맷 구조를 보는겁니다.
0x2200부터 0x2250까지 봤을 때, URL 크기, 메타 데이터의 크기, 데이터의 크기, 메타 데이터의 위치, 데이터의 위치 및 파일 이름을 확인할 수 있다고 하였는데 표시를 직접 해보겠습니다.

적혀있는 값들을 정리를 하겠습니다.
- 0x0101 = 257Byte (URL 크기)
- 0x17CC = 6092Byte (메타 데이터의 크기)
- 0x06E580 = 451,968Byte (파일 데이터의 크기)
★ - 0xC1030000 = 메타 데이터의 위치
★ - 0x80000001 = 데이터의 위치 및 이름
요 별로 된 부분은 다시 설명하겠습니다!!
URL의 크기가 0x0101 크기를 가지고 있다고 했는데, 한번 봅시다.
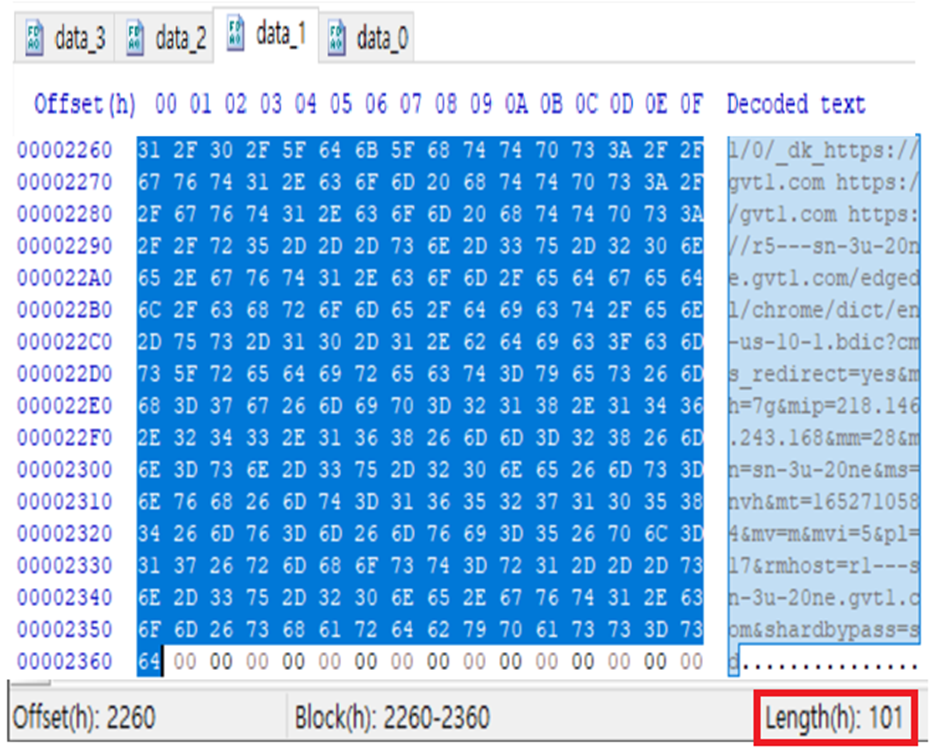
정확히 URL이 끝나는 시점에 길이가 101인것을 알 수 있었습니다.
다음은 메타 데이터의 크기 입니다.
메타 데이터의 크기는 메타 데이터의 위치와 연관되어 있습니다.
먼저 메타 데이터의 위치는 00 00 03 C1 이였습니다. 그래서 아까 배웠던 URL 위치 레코드를 계산하는 식으로 따라가면
0x0000 + 0x1000 + 0x2000 입니다. 결국엔 data_3 파일 오프셋 0x2000에 메타데이터가 저장이 되어있다는 뜻입니다.
그리고 메타 데이터의 크기는 0x17CC였습니다.

찾아가보면 data_3의 0x2000오프셋에서 메타데이터가 끝나는 시점의 오프셋인 37CB까지 범위를 지정했을 때, 17CC임을 알 수 있었습니다.
다음은 파일 데이터의 크기입니다.
파일 데이터의 크기는 데이터의 위치 및 파일 이름이랑 연관되어 있습니다.
먼저, 데이터의 위치 및 파일 이름을 보면 10 00 00 80임을 알 수 있습니다. 밑에 자료는 제 ppt입니다.

보시면 마지막 4바이트가 80인 것을 확인할 수 있는데, 설명과 같이 0x80일 경우 data_N 파일에 캐시 데이터가 저장되는 것이 아니라 f_000~으로 따로 캐시 데이터 파일이 저장됨을 알 수 있습니다. 만약 0x80이 아닐 경우에는 똑같이 오프셋을 계산해서 따라 가시면 됩니다.
그럼 80일 경우에는 앞에 3바이트가 파일의 이름이 되는데 리틀 엔디안으로 0x000001이 됩니다. 그럼 여기까지 정리를 해봅시다.
분석하고 있는 캐시 데이터는 data_N 형식에 캐시 데이터가 저장되어 있는 것이 아니라, f_000001이라는 파일명을 가진 파일에 캐시 데이터가 저장 되어 있다. 라고 생각하고 f_000001파일의 속성을 봅시다.

아까 제가 데이터의 크기랑 연관되어 있다고 했었는데, 그 이유가 이제 볼 수 있습니다.
계산했던 데이터의 크기와 캐시 데이터 파일의 크기가 동일함을 알 수 있습니다. 이렇게 캐시 데이터의 위치 및 파일을 찾아가면 되고, 캐시 데이터에도 2가지로 분류가 됩니다.

보시면 왼쪽에는 확장자가 GIF로 되어있는 캐시 이미지 파일이고, 우측에는 확장자가 없는 텍스트 데이터 파일입니다.
이 차이점만 아시면 될 것 같습니다!!! 모르시는것이 있으면 댓글 남겨 주세요! 성의껏 작성을 해드리겠습니다.
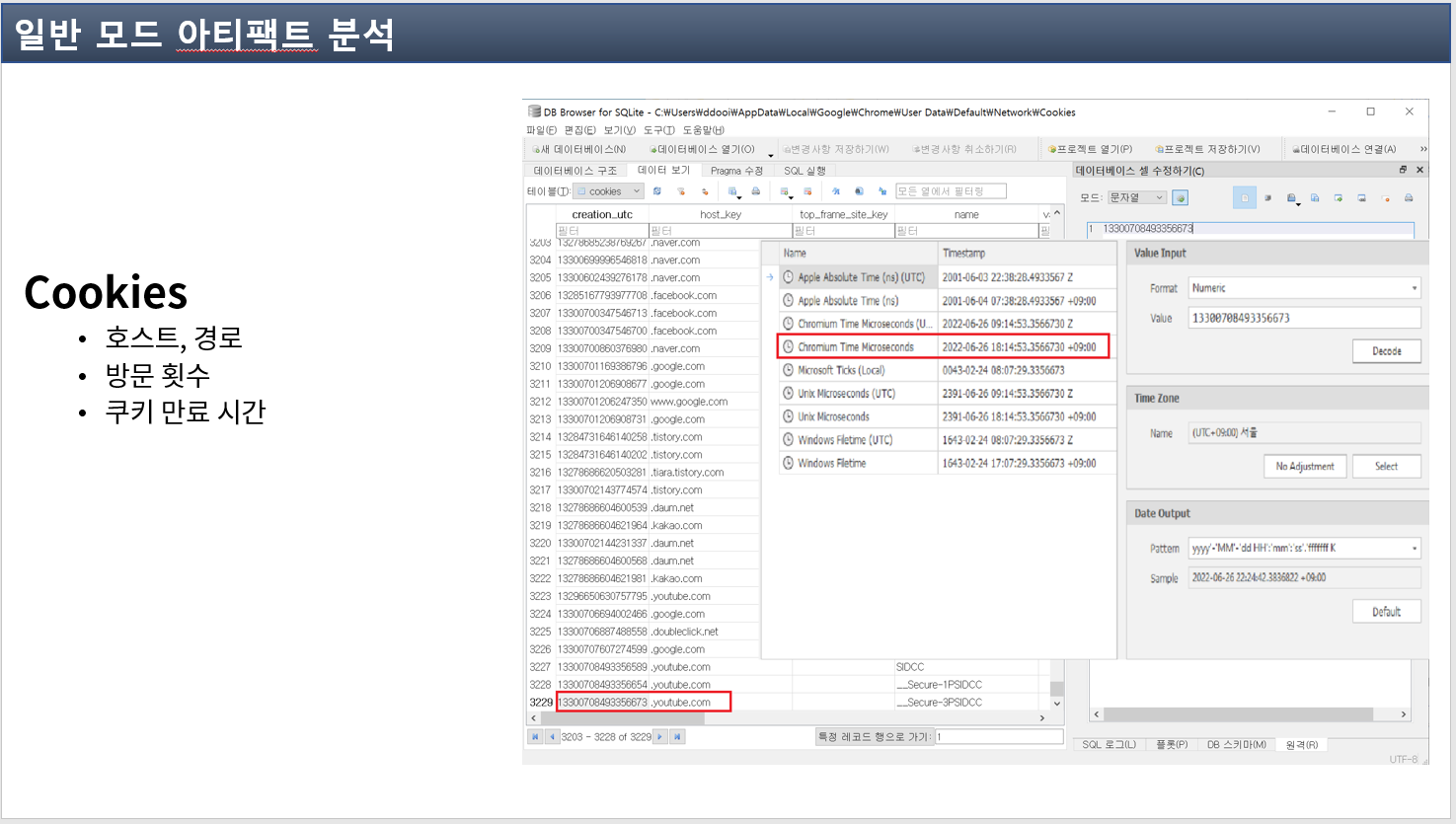
쿠키는 이제 호스트, 경로, 방문 횟수, 쿠키 만료 시간을 확인할 수 있는데, 타임 스탬프를 보면 133~~로 되어있는것을 타임스탬프 변형을 해보면 1960년이 나오는것을 확인할 수 있었습니다. 그래서 dcode 프로그램으로 변형을 시켜보니 크로미엄 타임 마이크로세컨드로 크로미엄 오픈소스를 활용한 웹 브라우저에서 타임 스탬프를 남기는 기록을 찾을 수 있었습니다.

마지막으로 비교를 해보면 표와 같이 확인할 수 있었습니다.
'Forensic > Forensic 이론' 카테고리의 다른 글
| 슬랙 공간 영역(Slack Space Area) (0) | 2022.07.10 |
|---|---|
| 반도체를 이용한 저장매체 (0) | 2022.03.31 |
| 파일 카빙(Carving) (0) | 2022.01.27 |
| 해쉬 함수 (Hash Function) (0) | 2022.01.20 |
| 데이터 인코딩(Data Encoding) (0) | 2022.01.18 |